Nepto
Web3 SocialFi Messenger & CommunityWeb3 SocialFi Messenger & Community
1. 프로젝트 개요1. Project Overview
블록체인 지갑 기반 인증, NFT 게이팅 커뮤니티, E2E 암호화 DM, 토큰 리워드 등 Web3 네이티브 기능을 결합한 메시징 플랫폼. 마이크로 서비스 아키텍처(MSA) 기반 시스템을 설계 및 구현A messaging platform combining Web3-native features — wallet-based auth, NFT-gated communities, E2E encrypted DMs, token rewards. Designed and implemented the MSA-based system
| 항목Item | 내용Details |
|---|---|
| 프로젝트명Project | Nepto |
| 분류Category | Web3 SocialFi Messenger & Community |
| 개발 기간Period | 약 2년 8개월 (2023.01 ~ 2025.08)~2 years 8 months (Jan. 2023 – Aug. 2025) |
| 팀 규모Team Size | 10명 (백엔드 3명)10 members (3 backend) |
| 역할Role | Backend DeveloperBackend Developer |
| 링크Link | https://nepto.com/ |

2. 프로젝트 배경과 기술 스택2. Background and Tech Stack
Web3 메신저 특성상 실시간 메시징, 블록체인 온체인 데이터 동기화, E2E 암호화, 대규모 커뮤니티 알림 등 서로 다른 특성의 도메인이 공존해야 했다. 각 도메인을 독립적으로 스케일링하고 장애를 격리하기 위해 MSA 아키텍처를 채택했다.The nature of a Web3 messenger required coexistence of domains with different characteristics — real-time messaging, blockchain on-chain data sync, E2E encryption, and large-scale community notifications. MSA architecture was adopted to independently scale each domain and isolate failures.
| 분류Category | 기술Technologies |
|---|---|
| Language | Python (FastAPI) / Rust (Background Worker) |
| Framework | FastAPI, Typer (CLI / Worker) |
| Database | MongoDB (Atlas), DynamoDB |
| Message Queue | AWS SNS + SQS (FIFO / Standard, Pub / Sub Event Driven) |
| Cloud | AWS (EKS, S3, SNS, SQS, DynamoDB, API Gateway, ECR) |
| Blockchain | Solidity, Web3.py, Alchemy API |
| Infra | Kubernetes (EKS), Terraform (IaC), Karpenter & HPA, Docker, GitHub Actions (CI / CD) |
| Realtime | WebSocket (AWS API Gateway) |
| Observability | Prometheus / Fluent Bit / Grafana / AWS OpenSearch & Kibana |
| Push | Firebase Cloud Messaging (FCM) |
기술 선택과 근거Technology Choices and Rationale
| 기술Technology | 선택 근거Rationale |
|---|---|
| SNS Pub/Sub + SQS | 이벤트가 많아 직접 Enqueue 시 관리포인트 폭증 + 일관성 문제. SNS로 느슨한 결합 확보, 순서 보장이 필요한 큐는 FIFO, 알림처럼 처리량이 중요한 큐는 Standard로 구분Direct enqueue causes management point explosion + consistency issues with many events. SNS for loose coupling, FIFO for order-critical queues, Standard for throughput-critical queues like notifications |
| MongoDB Atlas | 서비스별 독립 인스턴스로 데이터 격리(Service-per-Database). Document 모델이 다양한 도메인 스키마에 유연하게 대응Per-service independent instances for data isolation (Service-per-Database). Document model flexibly handles diverse domain schemas |
| DynamoDB | WebSocket 커넥션 상태 추적에 서버리스 환경 + TTL 자동 관리가 적합. Redis 대비 프로비저닝 관리 불필요Serverless + automatic TTL management ideal for WebSocket connection tracking. No provisioning management needed vs Redis |
| Rust (Background Worker) | Python 스크립트 언어 특성상 CPU-bound 집계 작업에 한계. 동일 로직 Rust 구현으로 67% 성능 개선Python scripting language has fundamental CPU-bound computation limits. Same logic in Rust achieved 67% performance improvement |
3. 시스템 아키텍처3. System Architecture
11개 API Server + 8개 Queue Worker + 1개 Background Worker(크론잡 15개+)로 구성된 MSA 시스템을 설계 및 구현했다. API Server는 도메인 바운디드 컨텍스트(인증, 메시징, 커뮤니티, 자산, 알림 등) 기준으로, Queue Worker는 SQS 큐 단위 1:1 매핑으로 분리하여 장애 격리와 독립 스케일링을 확보했다.Designed and implemented the entire MSA system consisting of 11 API Servers + 8 Queue Workers + 1 Background Worker (15+ cron jobs). API Servers were separated by domain bounded context (auth, messaging, community, assets, notifications, etc.), and Queue Workers were mapped 1:1 per SQS queue for fault isolation and independent scaling.
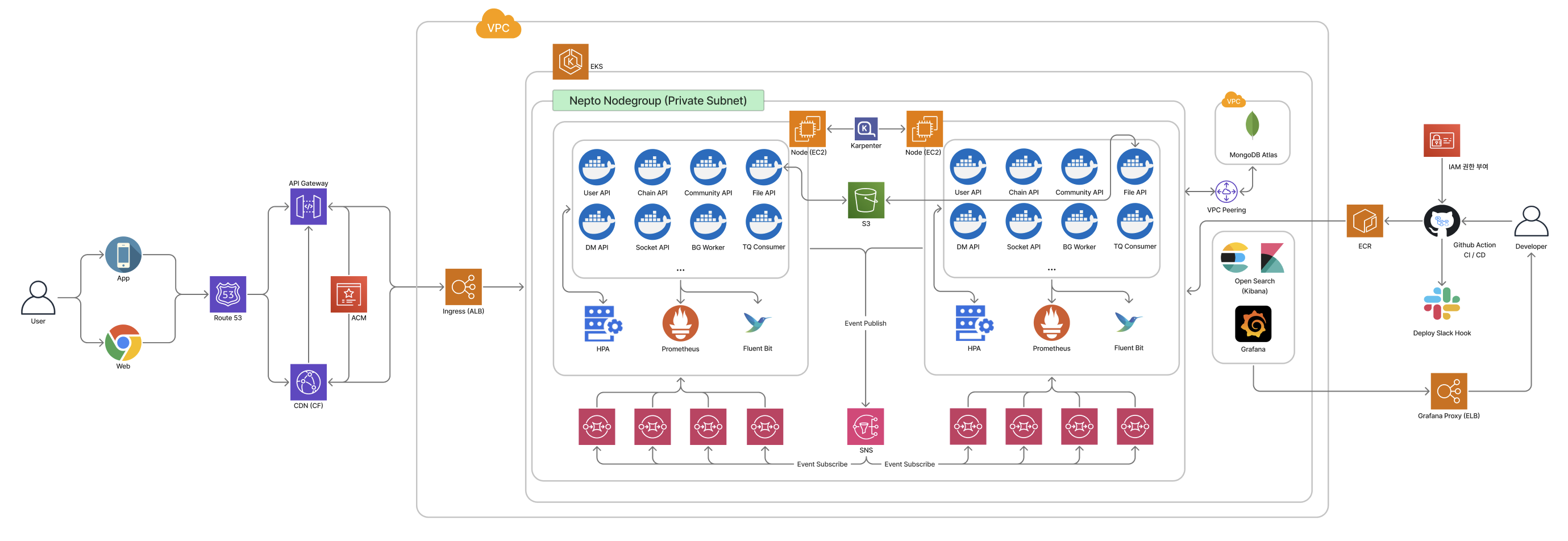
- 이벤트 드리븐: DM, 커뮤니티, 리워드, 알림, 온체인 추적 등 모든 도메인 간 통신이 SNS 기반 Pub / Sub → SQS FIFO / Standard 8개 큐로 Fan-Out되는 비동기 메시징 구조. 각 서비스가 목적에 맞는 Topic을 독립 구독하며, 자체 설계한 MessageV1 포맷으로 큐 메시징 통신 규격을 통일Event-Driven: All inter-domain communication (DM, community, rewards, notifications, on-chain tracking) flows through SNS-based Pub / Sub → Fan-Out to 8 SQS FIFO / Standard queues. Each service independently subscribes to purpose-specific Topics, with standardized queue messaging via custom-designed MessageV1 format
- 데이터 격리: Service-per-Database 패턴 (MongoDB Atlas 서비스별 독립 인스턴스)Data Isolation: Service-per-Database pattern (independent MongoDB Atlas instances per service)
- 오토스케일링: Karpenter (Node) + HPA (Pod) 기반 자동 확장, ConfigMap / Secret 환경 분리 (dev / alpha / prod)Autoscaling: Karpenter (Node) + HPA (Pod) auto-scaling, ConfigMap / Secret environment separation (dev / alpha / prod)
- Observability: Prometheus + Fluent Bit → Grafana / AWS OpenSearch & Kibana, 5xx 에러 Slack 실시간 알림Observability: Prometheus + Fluent Bit → Grafana / AWS OpenSearch & Kibana, 5xx error Slack real-time alerts
- Smart Contract: NeptoStaking (Solidity, Foundry, ERC20 토큰 스테이킹, 시간 범위 기반 APR 보상 계산)Smart Contract: NeptoStaking (Solidity, Foundry, ERC20 token staking, time-range-based APR reward calculation)
배포 전략 (CI / CD)Deployment Strategy (CI / CD)
AWS EKS(us-east-1)에 배포하며, GitHub Actions 기반 CI / CD 파이프라인을 자동화했다.Deployed on AWS EKS (us-east-1), with GitHub Actions-based CI / CD pipeline automation.
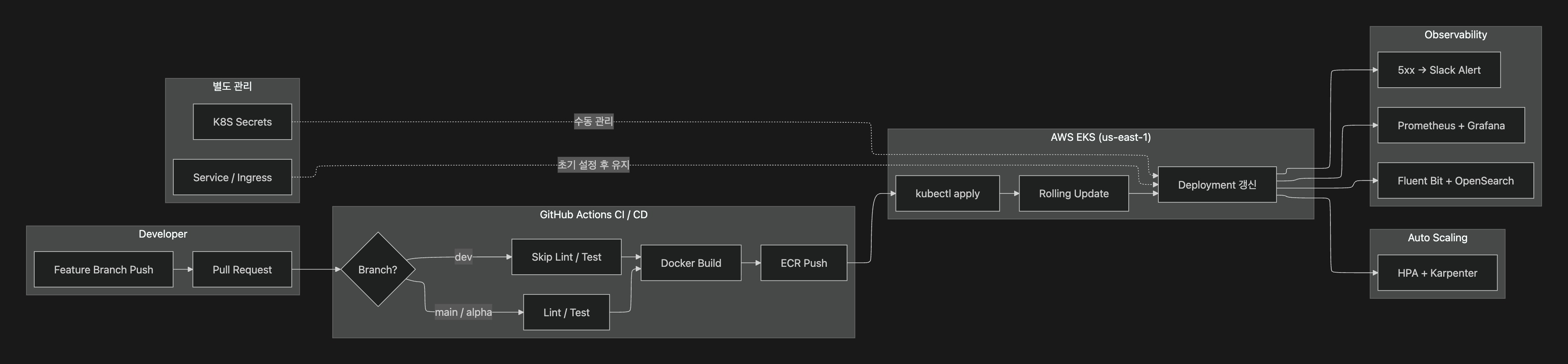
- ECR + EKS 기반 컨테이너 배포: Docker 이미지를 ECR에 Push하고, EKS Deployment를 Rolling Update 방식으로 무중단 배포ECR + EKS container deployment: Push Docker images to ECR, zero-downtime deployment to EKS Deployment with Rolling Update
- Git Flow 브랜치 전략:
main(프로덕션) →alpha(스테이징) →dev(개발) →feat-*(피처 개발) 브랜치를 운영하고, 3개 환경(main / alpha / dev)을 분리 운영Git Flow branch strategy: Operatedmain(production) →alpha(staging) →dev(development) →feat-*(feature development) branches, with 3 isolated environments (main / alpha / dev) - Lint / Test 자동화: Production(main) 및 Staging(alpha) 배포 시 코드 품질 검증을 내장 (Dev 환경은 빠른 배포를 위해 생략)Automated Lint / Test: Built into Production (main) and Staging (alpha) pipelines (Dev environment skips for faster deployment)
- Kubernetes 리소스 관리: Deployment / Service / Ingress / CronJob / Secret / ConfigMap / HPA / Karpenter 구성Kubernetes resource management: Deployment / Service / Ingress / CronJob / Secret / ConfigMap / HPA / Karpenter configuration
- Observability: Prometheus + Grafana 메트릭 모니터링, Fluent Bit + OpenSearch 로그 중앙 집중화, 5xx 에러 Slack 실시간 알림 (자세한 내용은 Observability Monitoring System 프로젝트 참고 ↗)Observability: Prometheus + Grafana metric monitoring, Fluent Bit + OpenSearch centralized logging, 5xx error real-time Slack alerts (see Observability Monitoring System project for details ↗)
4. 핵심 기술 구현4. Core Technical Implementation
4-1. E2E 암호화 DM & 실시간 메시지 전달 시스템4-1. E2E Encrypted DM & Real-time Message Delivery System
서비스 내 토큰 트랜잭션 및 지갑 서명 등 민감 정보 교환을 고려하여, 종단간 암호화 메시징(E2E Encrypted Messaging)과 실시간 WebSocket 기반 메시지 전달 시스템을 설계 및 개발했다.Considering sensitive information exchange such as token transactions and wallet signatures, an E2E Encrypted Messaging and real-time WebSocket-based message delivery system was designed and developed.
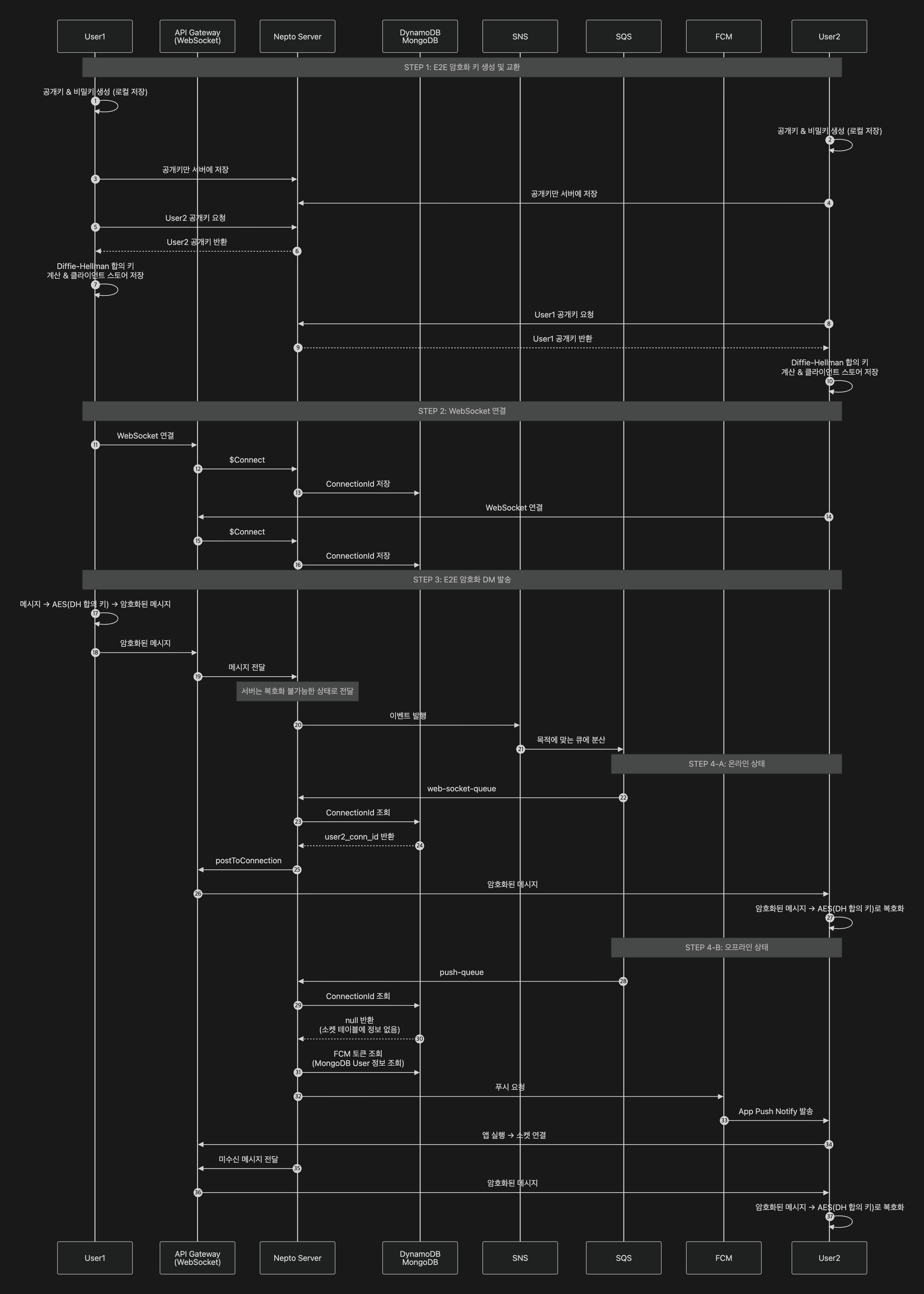
E2E 키 교환:E2E Key Exchange:
- 각 사용자가 공개키 / 비밀키를 로컬에서 생성, 공개키만 서버에 저장Each user generates public / private key locally; only public key stored on server
- 대화 시작 시 상대방의 공개키를 서버에서 조회하여 Diffie-Hellman 키 교환으로 합의 키 계산 (클라이언트 로컬 저장)On conversation start, retrieve counterpart's public key and compute shared key via Diffie-Hellman key exchange (stored locally)
WebSocket 연결 관리:WebSocket Connection Management:
- AWS API Gateway WebSocket + DynamoDB 연결 테이블(PK=user_id, SK=device_id)로 커넥션 상태를 추적. 연결 / 해제 이벤트를 SQS FIFO로 순서 보장하며, 실패 시 최대 3회 재시도Track connection state via AWS API Gateway WebSocket + DynamoDB connection table (PK=user_id, SK=device_id). Connection / disconnection events ordered via SQS FIFO, with up to 3 retries on failure
암호화 메시지 전송:Encrypted Message Transmission:
- AES(DH 합의 키)로 메시지 암호화 → 서버는 복호화 불가능한 상태로 전달 → SNS 이벤트 발행 → SQS Fan-Out으로 목적별 큐에 분산Encrypt with AES(DH shared key) → server relays without ability to decrypt → SNS event publish → SQS Fan-Out to purpose-specific queues
수신 (온라인 / 오프라인 분기):Delivery (Online / Offline Branching):
- 온라인: DynamoDB에서 ConnectionId 조회 → WebSocket
postToConnection으로 실시간 전달 → 수신 측에서 AES 복호화.GoneException(410)발생 시 FCM 폴백 + DynamoDB 정리,LimitExceededException(429)시 재시도Online: ConnectionId lookup from DynamoDB → real-time delivery via WebSocketpostToConnection→ receiver decrypts with AES. OnGoneException(410): FCM fallback + DynamoDB cleanup. OnLimitExceededException(429): retry - 오프라인: DynamoDB에 ConnectionId 없음 → MongoDB에서 FCM 토큰 조회 → App Push 발송 → 앱 실행 시 소켓 재연결 후 미수신 메시지 전달 → 복호화Offline: No ConnectionId in DynamoDB → FCM token lookup from MongoDB → App Push → socket reconnection on app launch → deliver missed messages → decrypt
피크 1,000명 동시 접속 기준 지연 < 50ms를 달성했으며, 서버리스 WebSocket으로 인프라 관리 부담을 최소화했다.Achieved < 50ms latency at peak 1,000 concurrent connections, with minimized infrastructure management overhead via serverless WebSocket.
→ 서버가 메시지 내용을 열람할 수 없는 구조로 사용자 프라이버시 보장. 암호화된 메시지는 서버에 최대 90일 TTL로 보관 후 자동 삭제→ Server cannot access message content, ensuring user privacy. Encrypted messages are stored on the server with a 90-day TTL and automatically deleted
4-2. Push Notification 시스템 (3단계 아키텍처 진화)4-2. Push Notification (3-Phase Architecture Evolution)
DM, 커뮤니티 채널, ADDM, 시스템 알림 등 다양한 알림 유형을 처리하는 Push Notification 시스템을 세 차례에 걸쳐 개선하며, 장애율을 0.1% 미만으로 낮췄다.The Push Notification system handling DM, community channels, ADDM, and system alerts was improved through three phases, reducing failure rate to under 0.1%.
Phase 1: API 직발송Direct API Dispatch
- API 요청 처리 중 FCM Push를 직접 발송하는 구조로, Push 발송이 API 응답 시간에 직접 영향을 주어 지연이 발생FCM Push dispatched directly during API request handling, where push delivery directly impacted API response time causing delays
- FastAPI
BackgroundTasks를 활용하여 응답 반환 후 Push를 발송하도록 개선해 응답 지연 문제는 해소Resolved response latency by deferring push dispatch after response return via FastAPIBackgroundTasks
- FastAPI
- 한계: 발송 실패 시 재시도 메커니즘이 없어 알림 누락 가능성이 존재했고, 트래픽 집중 시 단일 서버에서 처리하는 구조적 병목은 여전히 남아 있었다Limitations: No retry mechanism on delivery failure risking notification loss, and single-server processing bottleneck under traffic spikes remained
Phase 2: SQS 기반 비동기 처리SQS-based Async Processing
- DM 메시지는 정확성보단 신속성에 중점을 두어, DB 적재 방식에서 메시지 큐(AWS SQS) 도입Prioritizing speed over precision for DM messages, replaced DB-based approach with message queue (AWS SQS)
- 알림은 순차 처리 보장보다는 처리량이 더 중요하여 SQS Standard Queue를 채택Adopted SQS Standard Queue as throughput matters more than sequential processing for notifications
- 각각의 발송 엔트리 포인트에서, 목적과 상황에 맞게 메시지를 생성하고 online-queue-worker(Socket) / offline-queue-worker(FCM)에 라우팅하여 메시지 발송Each dispatch entry point creates messages according to purpose and context, routing to online-queue-worker (Socket) / offline-queue-worker (FCM) for delivery
- 한계: 각각의 서비스에 메시지 생성 관리 포인트가 산재되어있음 → 강한 디펜던시로 관리 포인트 폭증Limitation: Message creation management points scattered across services → management point explosion due to strong dependency
Phase 3: SNS Pub / Sub 이벤트 드리븐SNS Pub / Sub Event-Driven
Phase 2의 한계를 해결하기 위해, 각 서비스가 SQS에 직접 Enqueue하는 방식에서 SNS 기반 이벤트 드리븐 아키텍처로 전환했다.To address Phase 2's limitations, transitioned from direct SQS enqueue per service to an SNS-based event-driven architecture.
- 각 서비스는 SNS Topic에 도메인 이벤트만 발행 → SNS가 구독된 SQS 큐(알림, DM 전달, 온체인 추적 등)로 자동 Fan-OutEach service only publishes domain events to SNS Topic → SNS auto-fans out to subscribed SQS queues (notifications, DM delivery, on-chain tracking, etc.)
- Publisher는 이벤트 발행만 담당하므로 관리 포인트가 대폭 축소 — 메시지 포맷 / 큐 설정 변경이 Consumer 단독으로 완결되고, 새 Consumer 추가 시 기존 코드 수정 불필요Publishers only handle event emission, significantly reducing management points — message format / queue config changes completed solely by Consumers, no existing code changes needed when adding new Consumers
MessageRouter를 구현하여 온라인 / 오프라인 디바이스를 자동 분류하고 최적 경로로 전달MessageRouterbuilt to automatically classify online / offline devices and route through the optimal path
- 디바이스 맵 구축: MongoDB에서 수신 대상의 디바이스 목록 조회 (FCM 토큰, 푸시 설정)Device map construction: Query target device lists from MongoDB (FCM tokens, push settings)
- 온라인 / 오프라인 분류: DynamoDB 소켓 연결 테이블에서 100건씩 배치 조회 (DynamoDB BatchGetItem 최대 100건 제한, 조회 지연 ~50ms 수준으로 실시간 라우팅에 영향 최소화)Online / offline classification: Batch query 100 at a time from DynamoDB socket table (BatchGetItem max 100 items, ~50ms latency minimizing impact on real-time routing)
- 온라인 → WebSocket
postToConnection실시간 전달 / 오프라인 → FCM App PushOnline → WebSocketpostToConnectionreal-time / Offline → FCM App Push - 실패 처리: WebSocket
GoneException(410)→ FCM 폴백 + DynamoDB 정리,LimitExceededException(429)→ 재시도Failure handling: WebSocketGoneException(410)→ FCM fallback + DynamoDB cleanup,LimitExceededException(429)→ retry
0.1% 미만 장애율 달성 메커니즘: SNS 자체 재시도 정책 + notification-queue-worker의 FCM 응답 코드별 재시도(Retryable 에러만 최대 3회) + WebSocket 실패 시 FCM 자동 폴백의 다층 안전망으로 메시지 누락을 최소화0.1% failure rate mechanism: SNS built-in retry policy + notification-queue-worker FCM response code-based retry (max 3 for retryable errors) + automatic FCM fallback on WebSocket failure — multi-layer safety net minimizing message loss
부하 테스트 (Locust): 3,000명 동시 사용자 기준 100RPS, CPU 60%, 메모리 45%, 평균 응답시간 220msLoad Test (Locust): 3,000 concurrent users — 100RPS, CPU 60%, Memory 45%, avg response 220ms
→ 필수 알림(DM, 트랜잭션 등) 누락을 사실상 제거하여 사용자 신뢰성 확보→ Virtually eliminated critical notification (DM, transactions) loss, securing user trust
4-3. 데이터 정합성 설계 — 동시성 제어 + 출금 파이프라인4-3. Data Integrity Design — Concurrency Control + Withdrawal Pipeline
리워드 시스템에서 사용자 자산을 다루는 두 가지 핵심 문제가 있었다: (1) 동시 요청에 의한 리워드 중복 지급, (2) 출금 시 여러 컬렉션에 걸친 원자적 처리. 두 문제 모두 사용자 자산의 정확성이라는 동일한 비즈니스 요구에서 출발했다.Two critical problems arose in handling user assets within the reward system: (1) duplicate reward distribution from concurrent requests, and (2) atomic processing across multiple collections during withdrawal. Both stemmed from the same business requirement: user asset accuracy.
동시성 제어:Concurrency Control:
사용자별 요청 Limit 기능(예: 커뮤니티당 하루 20회 제한)에서 동시 요청 시 Limit을 초과하여 리워드가 지급되는 문제가 발생했다. 개별 사용자와 커뮤니티 단위의 동시성 특성이 달라, 레벨별로 전략을 분리했다.Per-user request limits (e.g., 20/day per community) were being exceeded under concurrent requests, causing over-distribution of rewards. Since per-user and per-community concurrency characteristics differ, strategies were separated by level.
- 개별 사용자: MongoDB Unique Index 기반 Mutex Lock — Lock Document Insert 성공 = Lock 획득, TTL Index로 비정상 종료 시에도 자동 해제. 밀리초 단위의 짧은 Lock으로 충분Per-user: MongoDB Unique Index-based Mutex Lock — successful Lock Document insert = lock acquired, TTL Index for automatic release on abnormal termination. Millisecond-level short locks suffice
- 커뮤니티 단위: SQS FIFO
GroupID = community_id로 동일 커뮤니티 요청을 순차 처리, 서로 다른 커뮤니티는 병렬 처리Per-community: SQS FIFOGroupID = community_idfor sequential processing within the same community, parallel across different communities - Redis vs MongoDB 판단: Redis Distributed Lock도 검토했으나, 이미 서비스별 MongoDB Atlas 인스턴스를 운영하고 있고 당시 트래픽 규모에서 별도 인프라 추가 없이 기존 MongoDB만으로 충분하다고 판단Redis vs MongoDB decision: Redis Distributed Lock was evaluated, but with per-service MongoDB Atlas instances already in place and traffic scale at the time, existing MongoDB was sufficient without additional infrastructure
출금 파이프라인:Withdrawal Pipeline:
출금 시 잔액 차감 + 트랜잭션 생성 + 로그 기록이 원자적이어야 했다. 리워드가 여러 소스(일일 보상, 이벤트, 레퍼럴 등)에서 개별 레코드로 쌓이므로, 단순 잔액 필드 차감이 아니라 오래된 리워드부터 FIFO로 소진하는 구조가 필요했다.Withdrawal required atomicity across balance deduction, transaction creation, and log recording. Since rewards accumulate as individual records from multiple sources (daily, events, referrals), a FIFO consumption structure — spending oldest rewards first — was needed instead of simple balance field deduction.
- MongoDB 세션 기반 트랜잭션: 잔액 정렬 후 누적 계산으로 출금 대상 선별, 전액 소진된 리워드는 delete / 부분 소진은 update로 분리, RewardLog + Transaction 동시 생성을 단일 원자 연산으로 처리MongoDB session-based transaction: Select withdrawal targets via sorted cumulative calculation, separate delete (fully consumed) / update (partially consumed), simultaneous RewardLog + Transaction creation as a single atomic operation
- 이중 안전: MongoDB ACID 트랜잭션으로 원자성 보장 + 멱등성 키(
idempotency_key) Unique Index로 클라이언트 재시도 시 중복 클레임 원천 차단Dual safety: MongoDB ACID transaction for atomicity +idempotency_keyUnique Index to prevent duplicate claims on client retries
→ 리워드 중복 지급 및 출금 정합성 이슈 0건, 별도 인프라(Redis 등) 없이 기존 스택만으로 자산 안전성 확보→ Zero duplicate reward distribution and withdrawal integrity issues, achieving asset safety with existing stack without additional infrastructure (Redis, etc.)
4-4. 온체인 자산 소유권 추적 시스템4-4. On-Chain Asset Ownership Tracking

블록체인의 모든 토큰 트랜잭션 및 이벤트를 실시간 추적하여, 사용자의 자산 변화를 감지하고 시스템 권한(NFT 게이팅, 역할 부여)에 자동 반영하는 Tokengate 시스템을 구축했다.Built a Tokengate system that tracks all blockchain token transactions and events in real-time, detects user asset changes, and automatically reflects them in system permissions (NFT gating, role assignment).
- 컨트랙트 주소 기반 이벤트 수집: Nepto에 등록된 커뮤니티(특정 토큰 컨트랙트)의 컨트랙트 주소를 필터링하여, 해당 컨트랙트에서 온체인상에 발생하는 Transfer / Approval 등의 이벤트만 선별적으로 수집Contract address-based event collection: Filters contract addresses of communities (specific token contracts) registered in Nepto, selectively collecting only Transfer / Approval events occurring on-chain for those contracts
- Blockchain Wallet 서명 인증: Private Key ECDSA Signing으로 지갑 소유권 검증 → 안전한 로그인Wallet Signature Auth: Wallet ownership verification via Private Key ECDSA Signing → secure login
- NFT 게이팅: ERC721 / ERC20 홀더 자동 역할 부여, HMA(Holder Minimum Amount) 설정, 채널별 RBACNFT Gating: Auto role assignment for ERC721 / ERC20 holders, HMA setting, per-channel RBAC
스테이킹 이벤트 추적 (이중 수집 체계):Staking Event Tracking (Dual Collection System):
초기에는 Alchemy WebHook 단독으로 운영했으나, Provider 측 장애 및 네트워크 지연으로 실제 이벤트 누락이 발생했다. 또한 단일 파이프라인에서 모든 이벤트 타입을 처리하다 보니, 특정 이벤트 타입의 장애가 전체 수집에 영향을 미쳤다. 이를 해결하기 위해 이중 수집 체계 + 독립 파이프라인으로 리팩토링했다.Initially operated with Alchemy WebHook alone, but actual event loss occurred due to provider-side failures and network delays. Additionally, processing all event types in a single pipeline meant one event type's failure affected the entire collection. This was resolved by refactoring into a dual collection system with independent pipelines.
- 1차 (실시간): Alchemy WebHook Notify로 실시간성 확보Primary (real-time): Real-time coverage via Alchemy WebHook Notify
- 2차 (보완): 자체 Background Staking Event Watcher — 5개 Event별 독립 파이프라인으로 이벤트 타입별 책임 분리, 특정 블록 구간 재시도 가능, 한 이벤트 타입 장애가 타 이벤트에 영향 없음Secondary (supplemental): Custom Background Event Watcher — 5 independent pipelines per event type for responsibility separation, block-range retries, and fault isolation between event types
- RPC Provider 장애 대응: 다수 Public Provider 헬스체크 + 자동 순환, 장애 시 유료 Provider(Alchemy) 자동 FailoverRPC Provider Resilience: Multi-provider health check + auto-rotation, automatic failover to paid provider (Alchemy)
→ 이중 수집 체계로 블록체인 이벤트 손실율 0% 확보, NFT 게이팅 및 자산 권한의 실시간 정합성 보장→ Dual collection system achieves 0% blockchain event loss rate, ensuring real-time consistency of NFT gating and asset permissions
4-5. ADDM (Ad DM) — 온체인 광고 메시징4-5. ADDM (Ad DM) — On-Chain Ad Messaging
블록체인 토큰 전송을 활용한 광고 DM 시스템. 특정 커뮤니티의 사용자 지갑으로 소량의 Nepto Token과 메시지를 일괄 전송하여, 앱 사용자에게는 Push 알림으로, 비사용자에게는 지갑 토큰 수신 자체로 메시지를 전달하는 구조이다.An ad DM system leveraging blockchain token transfers. Sends small amounts of Nepto Token with messages to community members' wallets in bulk — delivering messages via Push notifications for app users and wallet token receipt itself for non-users.
- Multi-Sender Contract를 통해 커뮤니티 사용자 지갑에 Nepto Token + 메시지를 일괄 전송 (ADDM 수신 거부 옵트아웃 사용자 제외)Bulk send Nepto Token + message to community members' wallets via Multi-Sender Contract (excluding users who opted out of ADDM)
- Background에서 Multi-Sender Contract 이벤트를 24시간 추적 (기존 이중 수집 체계 활용)24-hour tracking of Multi-Sender Contract events in background (leveraging existing dual collection system)
- 이벤트 감지 시 수신자(앱 사용자)에게 Push 알림 + 노티센터 노출On event detection, expose Push notification + notification center to recipients (app users)
- 수신자가 ADDM을 확인하면 소량의 리워드 토큰 지급Small reward token granted when recipient confirms the ADDM
4-6. Background Worker Rust 마이그레이션4-6. Background Worker Rust Migration
- Python 기반 Background Worker에서 리더보드 100만 건+ 집계 시 CPU-bound 성능 한계가 있어, 동일 로직을 Rust로 마이그레이션했다. 전체 API를 Rust로 전환하는 것은 팀의 학습 비용과 개발 속도 저하가 컸기 때문에, CPU-bound 병목이 있는 Background Worker만 선별적으로 마이그레이션하여 비용 대비 효과를 극대화했다CPU-bound aggregation bottleneck (1M+ leaderboard records) in Python Background Worker led to migrating identical logic to Rust. Full API migration was ruled out due to team learning cost and development velocity impact — selectively migrating only the CPU-bound Background Worker maximized cost-effectiveness
- 100만 건 기준 100초 → 33초로 약 67% 단축, 동일 로직 평균 50~60% 실행 시간 단축 → 리더보드 갱신 주기 단축으로 사용자에게 더 빠른 순위 반영1M records: 100s → 33s (~67% reduction), average 50–60% execution time reduction → faster leaderboard refresh for users
5. 성과 요약5. Achievement Summary
| 영역Area | 성과Achievement |
|---|---|
| MSA | MSA 시스템 전체 설계 및 구현, SNS Pub / Sub 이벤트 드리븐 아키텍처로 서비스 간 느슨한 결합 확보Full MSA system design & implementation, loose coupling via SNS Pub / Sub event-driven architecture |
| 장애 내성Fault Tolerance | Push Notification 장애율 0.1% 미만 달성, 3단계 아키텍처 진화Push Notification failure rate under 0.1%, 3-phase architecture evolution |
| 실시간Real-Time | MessageRouter 기반 온라인 / 오프라인 자동 라우팅, 피크 1,000명 동시 지연 < 50msMessageRouter-based online / offline auto-routing, peak 1,000 concurrent latency < 50ms |
| 부하 테스트Load Test | 3,000명 동시 사용자 기준 100RPS, 평균 응답시간 220ms3,000 concurrent users — 100RPS, avg response 220ms |
| 성능 최적화Performance | CPU-bound 집계 Rust 마이그레이션으로 100만 건 기준 약 67% 단축Rust migration for CPU-bound aggregation — ~67% reduction for 1M records |
| 보안Security | Diffie-Hellman + AES 기반 E2E 암호화 DM, 서버 복호화 불가 구조Diffie-Hellman + AES E2E encrypted DM, server cannot decrypt |
| Blockchain | 이중 수집 체계(WebHook + Watcher) 기반 실시간 자산 추적, 5개 이벤트별 독립 파이프라인으로 장애 격리Real-time asset tracking via dual collection (WebHook + Watcher), fault isolation with 5 independent pipelines per event type |
| 데이터 정합성Data Integrity | 레벨별 동시성 제어(MongoDB Mutex Lock + SQS FIFO) + ACID 트랜잭션 출금 파이프라인으로 리워드 중복 지급 및 출금 정합성 이슈 0건Level-separated concurrency control (MongoDB Mutex Lock + SQS FIFO) + ACID transaction withdrawal pipeline — zero duplicate reward and withdrawal integrity issues |