SOOJLE
AI 기반 대학생 정보 통합 및 개인화 추천 플랫폼AI-Powered Unified Information and Personalized Recommendation Platform for University Students
1. 프로젝트 개요1. Project Overview
200개 이상의 대학 관련 사이트에 분산된 정보를 통합하고, NLP 기반 개인화 추천 뉴스피드를 제공하는 플랫폼A platform that unifies information scattered across 200+ university-related sites and provides NLP-based personalized recommendation newsfeeds
| 항목Item | 내용Details |
|---|---|
| 프로젝트명Project Name | SOOJLE (세종대학교 정보 통합 솔루션)SOOJLE (Sejong University Unified Information Solution) |
| 분류Category | AI 기반 대학생 정보 통합 및 개인화 추천 플랫폼AI-powered unified information and personalized recommendation platform for university students |
| 개발 기간Development Period | 1년 4개월 (2019.03 ~ 2020.06)1 year 4 months (2019.03 ~ 2020.06) |
| 팀 규모Team Size | 3명 (AI, BE, FE)3 members (AI, BE, FE) |
| 역할Role | Backend DeveloperBackend Developer |
| 수상Awards | 8회 수상8 awards |
| GitHub | https://github.com/837477/SOOJLE |
| 문서Documentation | https://soojle.gitbook.io/project |

2. 프로젝트 배경과 동기2. Background and Motivation
장학금, 취업, 공모전, 학사 공지 등 대학생에게 필요한 정보는 200개 이상의 사이트에 파편화되어있다. 여러 사이트들을 직접 돌아다녀야 했고, 중요한 정보를 놓치는 일이 빈번했다.Information essential for university life — scholarships, employment, competitions, academic notices — was fragmented across 200+ sites. Students had to manually check multiple sites daily, frequently missing important information.
SOOJLE은 이러한 문제를 해결하기 위한 솔루션을 제시한다.
단순 정보 집계를 넘어, 개개인의 학생들에게 가장 필요한 정보를 먼저 보여주자 라는 목표를 세웠고, 학부 시절부터 AI 분야에 관심이 있던 만큼 NLP 기반의 개인화 추천 시스템을 기획하고 설계하는 방향으로 프로젝트를 발전시켰다.
3명으로 구성된 팀(AI, BE, FE)으로 약 1년 4개월간 프로젝트를 진행했으며, 어떻게 보면 개발자로서의 첫 발걸음이 된 프로젝트이다.SOOJLE was started to solve this problem. Beyond simple information aggregation, the goal was to "show each student the most relevant information first." With a keen interest in AI since university, the project evolved into directly planning and designing an NLP-based personalized recommendation system. Three team members divided AI, Backend, and Frontend roles and developed intensively for 1 year and 4 months — a project that became a decisive stepping stone for growth as a developer.
| 분류Category | 기술Technology |
|---|---|
| Language | Python |
| Framework | Flask |
| Database | MongoDB |
| NLP | KoNLPy (Komoran, Mecab), FastText, LDA (Latent Dirichlet Allocation) |
| Infra | Nginx + uWSGI + 학교 전산실 물리서버 (Ubuntu)Nginx + uWSGI + University Server Room Physical Server (Ubuntu) |
3. NLP 파이프라인3. NLP Pipeline
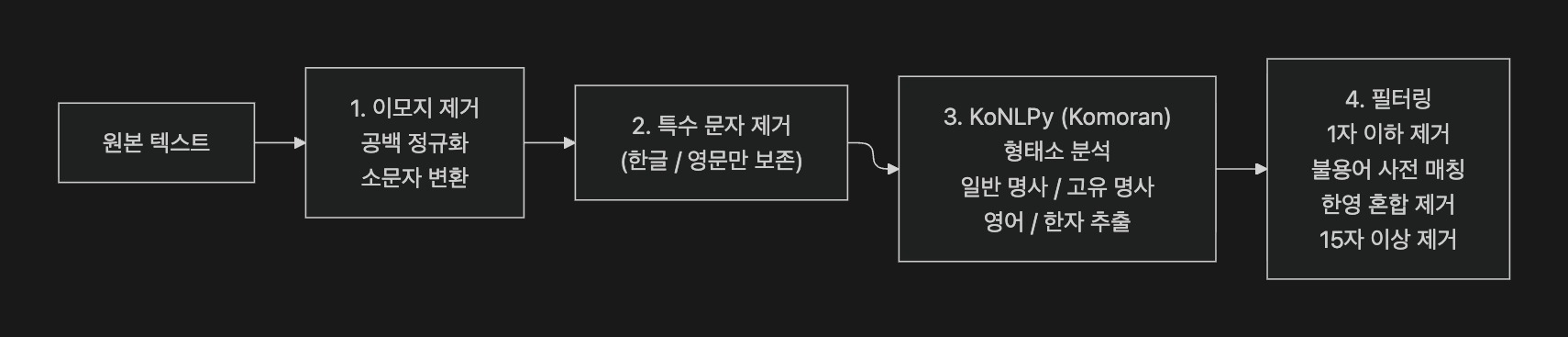
약 200개의 대학 생활과 관련된 사이트에서 수백만 건의 다양한 정보를 직접 수집하고, 원본 텍스트에서 형태소 분석과 불용어 필터링을 거쳐 정제된 토큰을 생성하여 토픽 모델링과 워드 임베딩에 활용하는 파이프라인을 구축했다. 형태소 분석기는 초기에 Komoran을 사용했으나, 처리 속도와 분석 정확도 개선을 위해 이후 Mecab으로 전환했다.A pipeline was built to generate clean tokens from collected raw text through morphological analysis and stopword filtering, then feed them into topic modeling and word embedding. The morphological analyzer was initially Komoran, but was later switched to Mecab for improved processing speed and analysis accuracy.
토픽 모델링 (LDA)Topic Modeling (LDA)
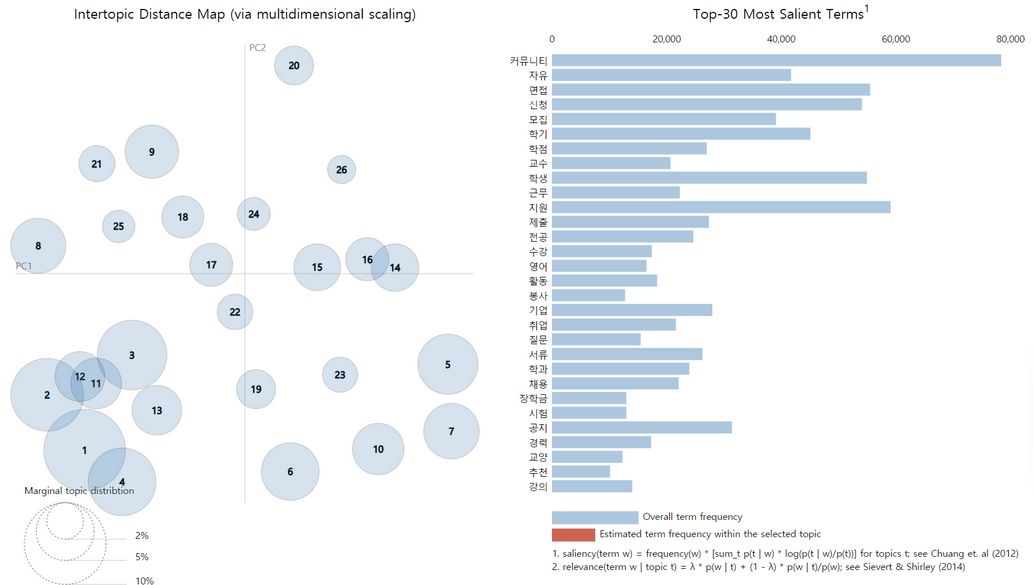
수집한 문서를 자동으로 주제별 분류하기 위해 Gensim 라이브러리 기반의 LDA(Latent Dirichlet Allocation)를 도입했다. 레이블이 없는 대량의 비정형 데이터에서 단어의 동시 출현 패턴을 분석하여 잠재 토픽을 비지도 학습으로 추출하는 방식으로, 학사, 장학금, 취업, 공모전 등 26개 토픽을 도출했다. 각 문서는 토픽별 확률 벡터로 표현된다.LDA (Latent Dirichlet Allocation) was introduced to automatically classify millions of documents by topic. By analyzing word co-occurrence patterns in large volumes of unlabeled unstructured data, latent topics were extracted through unsupervised learning — deriving 26 topics including academics, scholarships, employment, and competitions. Each document is represented as a probability vector across topics.
초기에는 출처 게시판과 제목 키워드 기반의 Rule 분류만 사용했으나, 짧은 게시글이나 특정 도메인에서 오분류가 빈번했다. LDA를 도입하고 Rule 기반과 결합한 하이브리드 방식을 적용하여 분류 정확도를 개선했다.Initially, only rule-based classification using source boards and title keywords was used, but misclassification was frequent for short posts and specific domains. LDA was introduced and combined with rule-based classification in a hybrid approach, improving classification accuracy.
워드 임베딩 (FastText)Word Embedding (FastText)
문서와 사용자 간 의미론적 유사도 측정을 위해 워드 임베딩이 필요했다. 한국어 특성상 조사 변형("장학금을", "장학금이"), 신조어, 오타 등 OOV(Out-of-Vocabulary) 문제가 빈번하여 서브워드(N-gram) 기반의 FastText를 선택했다. 학습 데이터에 없는 단어도 구성 N-gram으로부터 벡터를 추론할 수 있어 한국어 환경에 적합했다.Word embeddings were needed for semantic similarity measurement between documents and users. Due to frequent OOV (Out-of-Vocabulary) issues from Korean particle variations, neologisms, and typos, subword (N-gram) based FastText was chosen. It can infer vectors for unseen words from their constituent N-grams, making it well-suited for Korean language environments.
학습된 임베딩은 추천 시스템의 사용자-문서 유사도 측정과, 검색 시스템의 유사 토큰 확장에 각각 활용된다.The trained embeddings are used for user-document similarity measurement in the recommendation system, and for similar token expansion in the search system.

4. 추천 및 검색 시스템4. Recommendation and Search Systems
개인화 추천 뉴스피드Personalized Recommendation Newsfeed
사용자의 행동 데이터를 가중 종합하여 사용자 토픽 벡터(LDA)와 사용자 문서 벡터(FastText)를 생성하고, 다차원 유사도 기반으로 추천 스코어를 산출한다.User behavioral data is weighted and combined to generate a user topic vector (LDA) and a user document vector (FastText), calculating recommendation scores based on multi-dimensional similarity.
| 데이터 소스Data Source | 가중치Weight | 설명Description |
|---|---|---|
| 좋아요한 게시글Liked Posts | 40% | 가장 강한 관심 신호 — LDA 토픽 및 태그 분석Strongest interest signal — LDA topic and tag analysis |
| 열람한 게시글Viewed Posts | 30% | 조회했으나 직접 반응은 없는 약한 관심 신호Weak interest signal — viewed but no active engagement |
| 검색 키워드Search Keywords | 25% | 능동적으로 검색한 키워드의 토픽 분석Topic analysis of actively searched keywords |
| 접근한 뉴스피드Accessed Newsfeeds | 5% | 자주 보는 카테고리Frequently accessed categories |
Recommendation Score = ToS + TaS + IS + FaS + rand(X)| 요소Component | 설명Description |
|---|---|
| ToS (Topic Similarity) | 사용자 LDA 토픽 벡터와 문서 토픽 벡터 간 코사인 유사도Cosine similarity between user LDA topic vector and document topic vector |
| TaS (Tag Similarity) | 사용자 관심 태그와 문서 태그 간 집합 교집합Set intersection between user interest tags and document tags |
| IS (Issue Score) | 게시글 인기도 (좋아요 + 조회 수 정규화)Post popularity (likes + views normalized) |
| FaS (FastText Similarity) | 사용자 FastText 벡터와 문서 벡터 간 내적Dot product between user FastText vector and document vector |
| rand(X) | 필터 버블 방지를 위한 다양성 변수Diversity variable for filter bubble prevention |
즉, 토픽 유사도, 태그 매칭, 인기도, 임베딩 유사도를 가중 결합하여 사용자별 맞춤 추천 스코어를 산출하는 구조다.In short, a personalized recommendation score is calculated by combining topic similarity, tag matching, popularity, and embedding similarity with weighted aggregation.
검색 시스템Search System
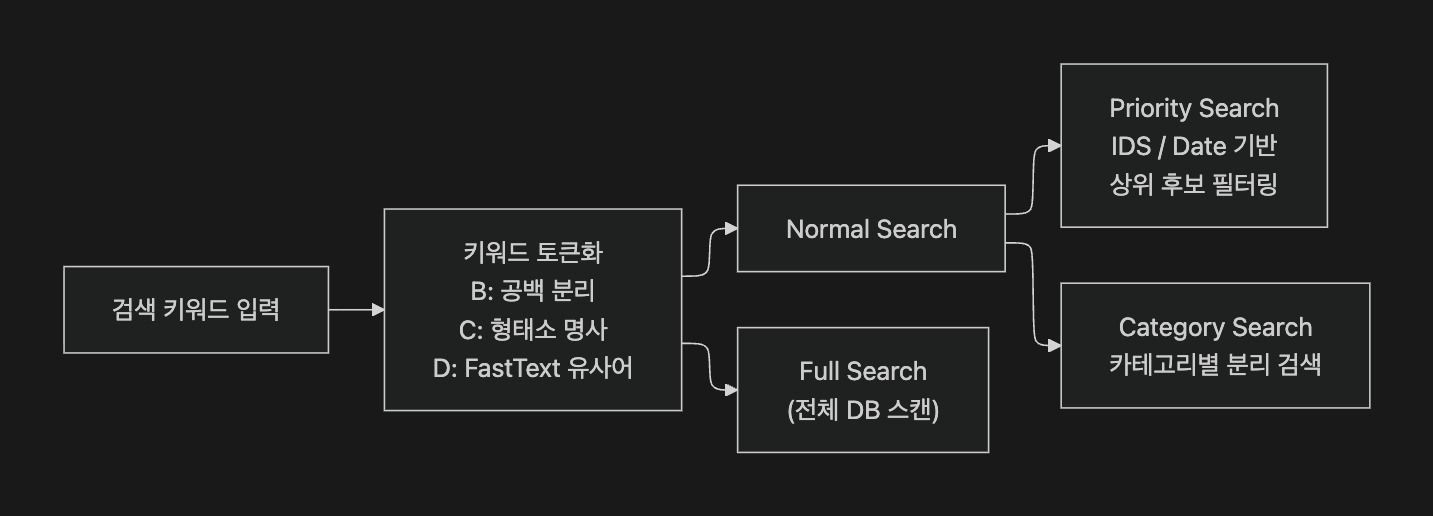
검색 키워드를 3단계로 토큰 확장하여 의미 검색을 구현했다.Semantic search was implemented by expanding search keywords through 3-stage tokenization.
| 단계Stage | 생성 방식Generation Method | 예시 (입력: "파이썬 프로그래밍 대회")Example (input: "파이썬 프로그래밍 대회") |
|---|---|---|
| 1단계Stage 1 | 공백 기반 분리Space-based split | ["파이썬", "프로그래밍", "대회"] |
| 2단계Stage 2 | 형태소 분석 (명사 추출)Morphological analysis (noun extraction) | ["파이썬", "프로그래밍", "대회"] |
| 3단계Stage 3 | FastText 유사 토큰 확장FastText-based similar token expansion | ["코딩", "알고리즘", "공모전", ...] |
공백 분리 → 형태소 분석 → FastText 유사어 확장의 3단계를 거쳐 검색 범위를 점진적으로 넓히는 구조다.Search scope is progressively expanded through 3 stages: space-based split → morphological analysis → FastText similar word expansion.
5. 성과 및 임팩트5. Results and Impact
200개 이상의 사이트에서 수백만 건의 데이터를 통합하고, NLP 기반 추천 시스템을 구축하여 총 8회 수상했다. 서울특별시, 과학기술정보통신부 주관 대회를 포함한 교내외 대회에서 꾸준히 인정받았다.A total of 8 awards were achieved, consistently recognized in both university and external competitions including Seoul Metropolitan Government and Ministry of Science and ICT events.
| 날짜Date | 수상명Award | 대회명Competition |
|---|---|---|
| 2019.10 | 최우수상Grand Prize | 인공지능 아이디어 경진대회AI Idea Contest |
| 2019.12 | 장려상Encouragement Award | 제 8회 창의설계경진대회8th Creative Design Competition |
| 2019.12 | 아이디어상Idea Award | 세종 창업 아이디어 페스티벌Sejong Startup Idea Festival |
| 2019.12 | 장려상Encouragement Award | 캠퍼스타운 활성화 공모전 (서울특별시)Campus Town Activation Contest (Seoul Metropolitan Government) |
| 2019.12 | 최우수상Grand Prize | 컴퓨터공학과 학술제CS Department Academic Festival |
| 2020.11 | 특별상Special Award | 제 1회 SW / AI 융합 메이커톤1st SW / AI Convergence Makeathon |
| 2020.12 | 특별상Special Award | 인공지능 아이디어 경진대회AI Idea Contest |
| 2020.12 | 동상Bronze Award | SW 스타트업 창업 챌린지 공모전 (과학기술정보통신부)SW Startup Challenge Contest (Ministry of Science and ICT) |
1년 4개월간 3명의 팀원과 함께 문제 정의부터 데이터 수집, NLP 모델링, 서비스 배포까지 전 과정을 경험했다. 단순히 기능을 구현하는 것을 넘어, 실제 사용자의 문제를 정의하고 데이터 기반으로 해결하는 경험을 통해 개발자로서의 시야를 넓힐 수 있었다.Over 1 year and 4 months with 3 team members, the entire process was experienced — from problem definition to data collection, NLP modeling, and service deployment. Going beyond simply implementing features, this experience of defining real user problems and solving them with data-driven approaches broadened perspectives as a developer.