Gracy 시스템 마이그레이션 및 리팩토링Gracy System Migration and Refactoring
AI 기반 HR 어시스턴트 플랫폼AI-powered HR Assistant Platform
1. 프로젝트 개요1. Project Overview
Slack 기반 HR Assistant 플랫폼. 조직 문화 활성화와 HR 데이터 분석을 하나의 서비스에서 제공한다.Slack-based HR Assistant platform. Provides organizational culture activation and HR data analytics in a single service.
| 항목Item | 내용Details |
|---|---|
| 프로젝트명Project | Gracy 시스템 마이그레이션 및 리팩토링Gracy System Migration and Refactoring |
| 분류Category | AI 기반 HR SaaS — Workplace Culture PlatformAI-powered HR SaaS — Workplace Culture Platform |
| 개발 기간Duration | 7개월 (2022.06 ~ 2022.12) — 이후 다른 프로젝트로 이전7 months (Jun 2022 – Dec 2022) — transitioned to another project |
| 팀 규모Team Size | 10명 (백엔드 3명)10 members (3 backend) |
| 역할Role | Backend Developer |
| 링크Link | https://www.gracy.ai/ https://staking.gracy.ai/ |
2. 프로젝트 배경과 기술 스택2. Background and Tech Stack
입사 후 첫 번째로 맡은 프로젝트로, 기존에 운영 중이던 Monolithic 아키텍처의 단일 장애점(SPOF), 비구조화된 배포, 환경 분리 부재 등의 문제를 해결하고, API 성능을 개선하는 것이 초기 핵심 과제였다.As the first project after joining the company, the initial core challenge was resolving issues in the existing Monolithic architecture — single point of failure (SPOF), unstructured deployment, and lack of environment separation — while improving API performance.
| 분류Category | 기술Technology |
|---|---|
| Language | Python |
| Framework | Django (HR API) / Flask (Slack Bot API) |
| Database | AWS Aurora PostgreSQL (HR API), MongoDB (Slack Bot API)AWS Aurora PostgreSQL (HR API), MongoDB (Slack Bot API) |
| Cloud | AWS (Lambda, EC2, API Gateway, S3, CloudFront, CloudWatch, CloudFormation, EventBridge, ECR) |
| Blockchain | Solidity (Staking Contract), Alchemy API, Web3.py |
| Infra | Zappa (Serverless Deployment), Docker, GitHub Actions (CI / CD) |
| SendGrid |
3. 시스템 아키텍처3. System Architecture
기술 선택과 근거Technology Choices and Rationale
| 기술Technology | 선택 근거Rationale |
|---|---|
| Zappa + Lambda | 기존 Django / Flask 코드 변경 최소화하면서 Serverless 배포 가능. 피크 / 오프피크 트래픽 차이가 커서 상시 서버 운영 대비 요청 기반 과금이 비용 효율적Serverless deployment with minimal code changes to existing Django / Flask. Large peak / off-peak traffic gap makes pay-per-request more cost-effective than always-on servers |
| Aurora PostgreSQL | HR 서비스의 관계형 데이터 모델링에 적합. RDS PostgreSQL 대비 읽기 성능 및 가용성 향상Suitable for HR service's relational data modeling. Improved read performance and availability over RDS PostgreSQL |
| MongoDB | Slack Bot의 이벤트 / 로그 등 유연한 스키마가 필요한 데이터에 적합Suitable for Slack Bot's events / logs requiring flexible schema |
| 도메인 분리Domain Separation | HR 데이터 조회와 Slack 이벤트 처리의 트래픽 패턴이 상이하여 독립 스케일링 필요 → HR API + Slack Bot API로 분리, DB도 각각 Aurora PostgreSQL / MongoDB로 분리Different traffic patterns between HR data queries and Slack event processing require independent scaling → Separated into HR API + Slack Bot API, with separate Aurora PostgreSQL / MongoDB databases |
3-1. 기존 아키텍처 (Monolithic)3-1. Legacy Architecture (Monolithic)
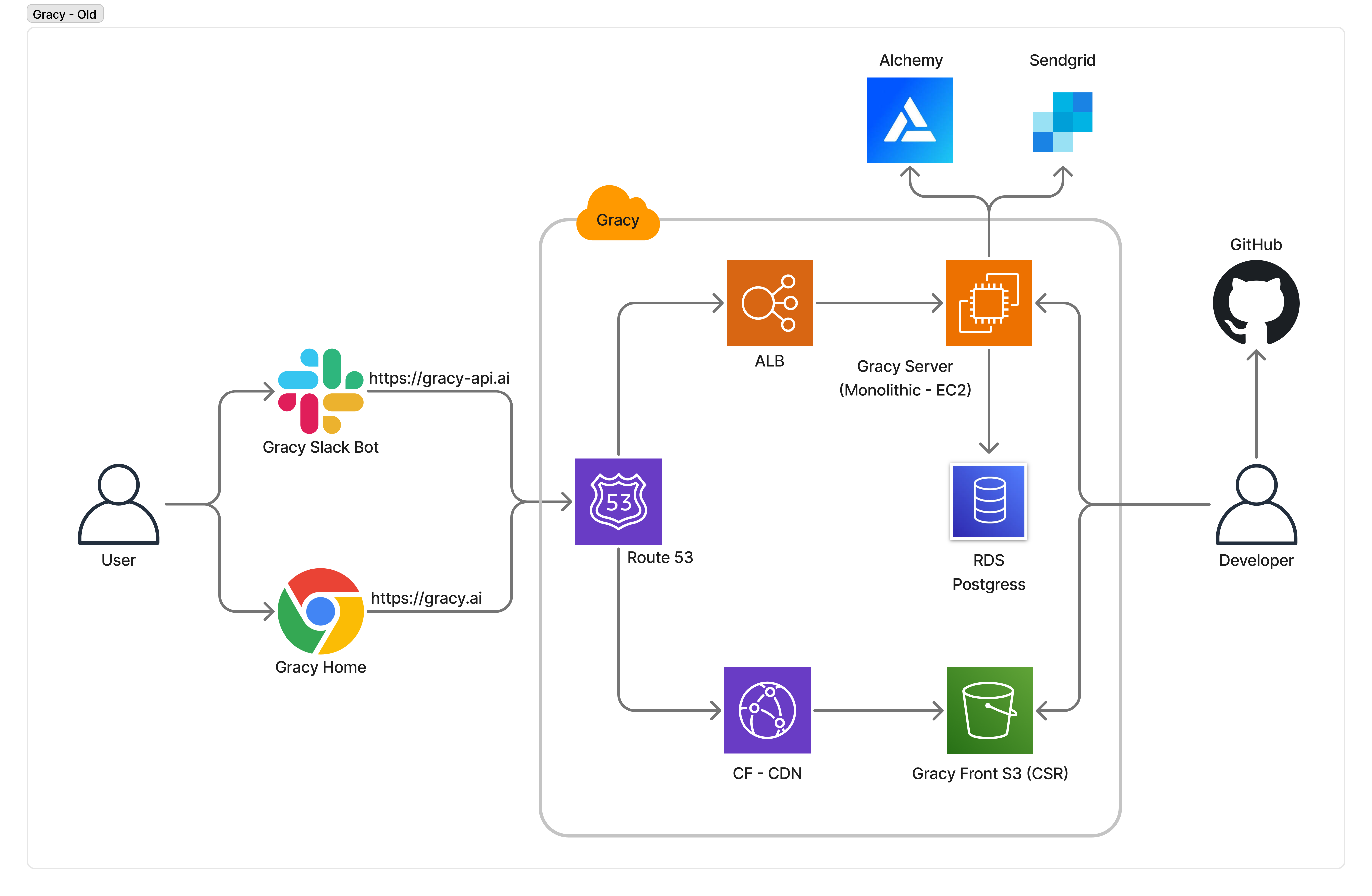
레거시 시스템은 고사양 EC2 인스턴스 단일 서버에 모든 서비스가 구동되는 모놀리식 구조였다.The legacy system was a monolithic architecture where all services ran on a single high-spec EC2 instance.
주요 문제점:Key Issues:
| 문제Issue | 상세Details |
|---|---|
| 단일 장애점(SPOF)Single Point of Failure (SPOF) | EC2 인스턴스 하나에 전체 서비스가 의존 — 장애 시 전체 서비스 중단Entire service dependent on a single EC2 instance — full outage on failure |
| 비체계적 배포Unstructured Deployment | SSH 직접 접속 → Shell Script 수동 배포 — 휴먼 에러 리스크, 롤백 불가Direct SSH → manual Shell Script deployment — human error risk, no rollback capability |
| 환경 미분리No Environment Separation | Prod / Dev 환경이 분리되지 않아 로컬에서 구현 → 테스트 → 곧바로 Prod 배포No Prod / Dev separation — local development → testing → direct Prod deployment |
| 과잉 프로비저닝Over-provisioning | 트래픽과 무관하게 고사양 인스턴스 상시 운영 → 비용 비효율High-spec instance running 24/7 regardless of traffic → cost inefficiency |
3-2. 개선 아키텍처 (Serverless + EC2)3-2. Improved Architecture (Serverless + EC2)
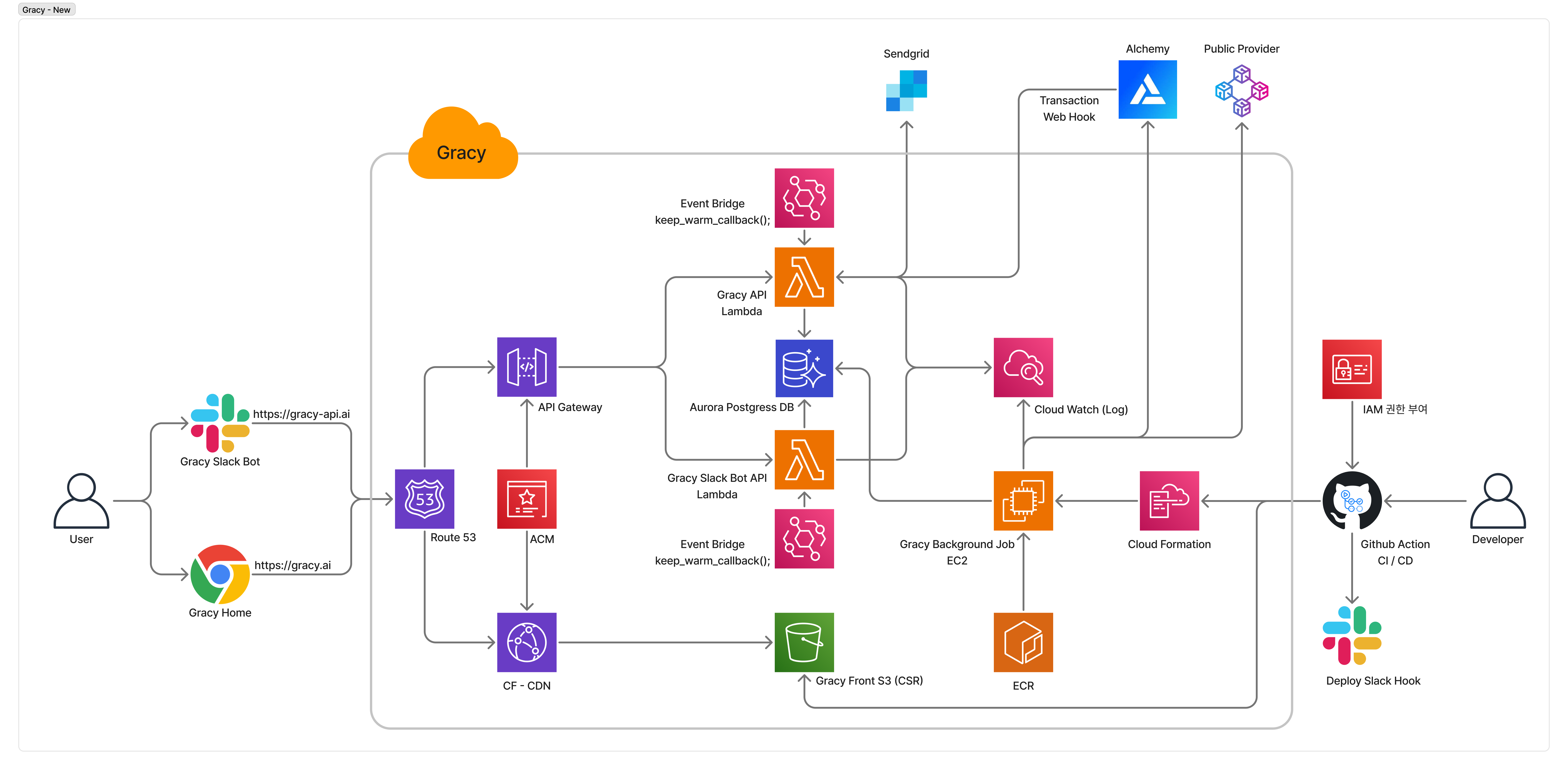
마이그레이션 전략:Migration Strategy:
최소한의 리소스와 빠른 전환 속도를 목표로, API 서버는 AWS Lambda 기반 Serverless 아키텍처로 전환하고, 백그라운드 워커(Staking, 크론 작업)는 EC2에서 Docker 컨테이너로 운영하는 하이브리드 구조로 마이그레이션했다.Targeting minimal resources and fast transition, API servers were migrated to an AWS Lambda-based Serverless architecture, while the background worker (Staking, cron jobs) operates as a Docker container on EC2 — a hybrid structure.
- Serverless 전환: Zappa Framework를 활용하여 기존 Django / Flask 앱을 Lambda로 배포 — 애플리케이션 코드 변경 최소화Serverless Migration: Deployed existing Django / Flask apps to Lambda using Zappa Framework — minimizing application code changes
- 도메인 분리: 모놀리식 구조를 HR Assistant API(Aurora PostgreSQL)와 Slack Bot API(MongoDB) 두 개의 독립 서비스로 분리하여, 서비스 간 강한 의존성 해제Domain Separation: Split the monolithic structure into two independent services — HR Assistant API (Aurora PostgreSQL) and Slack Bot API (MongoDB) — eliminating tight inter-service dependencies
- 환경 분리: Dev / Alpha / Prod 3개 환경을 Lambda 함수 및 EC2 인스턴스 단위로 완전 분리하여 시스템 안정성 확보Environment Isolation: Fully separated 3 environments (Dev / Alpha / Prod) at the Lambda function and EC2 instance level for system stability
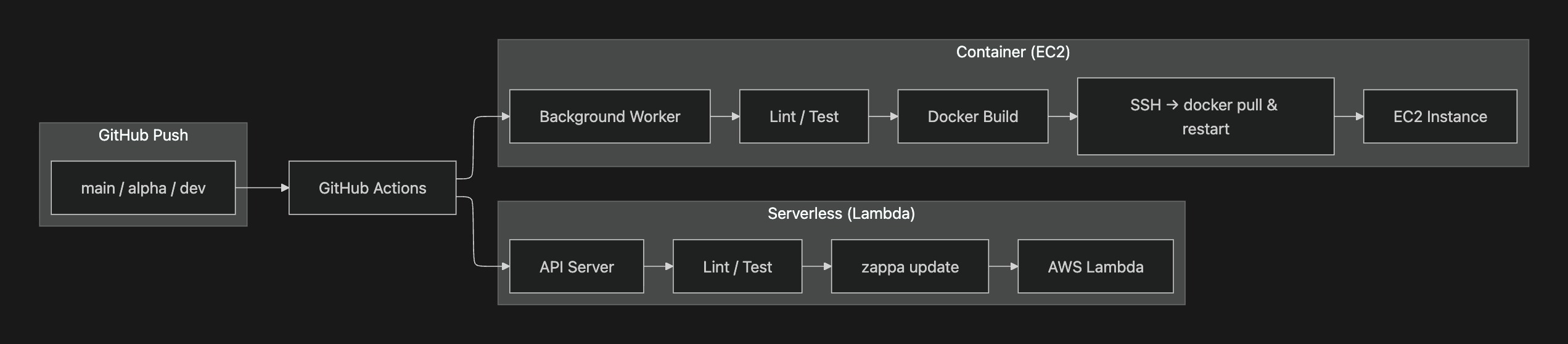
- CI / CD 구축: GitHub Actions 기반 자동 배포 파이프라인 구축 — API 서버는
zappa update로 Lambda 배포, 백그라운드 워커는 Docker Build → EC2 SSH 배포로 각 서버 특성에 맞게 분리CI / CD Pipeline: Built automated deployment pipeline with GitHub Actions — API server deployed to Lambda viazappa update, background worker deployed via Docker Build → EC2 SSH, separated by server characteristics
마이그레이션 성과:Migration Results:
| 지표Metric | Before | After |
|---|---|---|
| 인프라 비용Infra Cost | 고사양 EC2 상시 운영High-spec EC2 running 24/7 | 요청 기반 과금 — 50~60% 절감Pay-per-request — 50–60% reduction |
| 배포 방식Deployment | SSH + Shell Script 수동Manual SSH + Shell Script | GitHub Actions 자동 배포Automated via GitHub Actions |
| 환경 분리Environment | Prod 단일 환경Single Prod environment | Dev / Prod 완전 분리Fully separated Dev / Prod |
| 서비스 결합도Coupling | 모놀리식Monolithic | 도메인별 독립 배포Independent deployment per domain |
| 장애 격리Fault Isolation | 전체 서비스 영향Entire service affected | 서비스 단위 격리Isolated per service |
4. 핵심 기술 구현4. Core Technical Implementation
4-1. 백엔드 성능 개선 리팩토링4-1. Backend Performance Optimization
레거시 코드 전반에 대한 성능 프로파일링을 수행하고, 병목 지점을 분석하여 체계적으로 최적화를 진행했다. (Locust 부하 테스트 + django.db.connection.queries 기반 쿼리 분석)Performed performance profiling across the legacy codebase, analyzed bottlenecks, and carried out systematic optimization. (Locust load testing + django.db.connection.queries query analysis)
문제 진단Problem Diagnosis
| 문제Issue | 영향Impact |
|---|---|
| ORM N+1 Query | 관련 엔티티를 Lazy Loading으로 개별 조회 — 데이터 증가에 비례하여 쿼리 수 폭증Related entities fetched individually via Lazy Loading — query count grows proportionally with data |
| 비효율적 ERD 설계Inefficient ERD Design | 애플리케이션 레벨에서 Cartesian Product 방식의 Cross Join 다수 발생Numerous Cartesian Product-style Cross Joins at the application level |
| 앱 레벨 페이지네이션App-level Pagination | 전체 데이터를 DB에서 한번에 조회한 뒤 Python에서 슬라이싱 — 과도한 메모리 사용 및 응답 지연Fetched all data from DB at once then sliced in Python — excessive memory usage and response delay |
최적화 전략Optimization Strategy
1) 데이터베이스 마이그레이션 & ERD 재설계1) Database Migration & ERD Redesign
- RDS PostgreSQL → AWS Aurora PostgreSQL로 마이그레이션하여 읽기 성능 및 가용성 향상Migrated from RDS PostgreSQL to AWS Aurora PostgreSQL for improved read performance and availability
- ERD를 전면 재설계하여 DB 레벨에서 효율적인 Join이 가능한 정규화 구조로 전환Fully redesigned ERD into a normalized structure enabling efficient DB-level Joins
- 데이터 접근 패턴을 분석하여 적절한 인덱스 설계 및 적용Analyzed data access patterns and designed / applied appropriate indexes
2) ORM 레이어 최적화2) ORM Layer Optimization
- Lazy Loading → Eager Loading (select_related / prefetch_related) 전환으로 N+1 문제 해결Resolved N+1 problem by switching from Lazy Loading to Eager Loading (select_related / prefetch_related)
- 불필요한 애플리케이션 레벨 Cross Join 제거, DB 레벨 Join으로 대체Eliminated unnecessary application-level Cross Joins, replaced with DB-level Joins
3) 데이터 처리 방식 개선3) Data Processing Improvement
- 목록 API: 앱 레벨 슬라이싱 → DB 레벨 LIMIT / OFFSET 페이지네이션으로 전환List APIs: Switched from app-level slicing to DB-level LIMIT / OFFSET pagination
- 내부 로직: 전체 사용자 일괄 로드 → N건 단위 청크 배치 처리로 전환하여 메모리 사용량 최소화Internal logic: Full user bulk load → N-record chunk batch processing to minimize memory usage
성능 개선 결과Performance Results
Before (Legacy API)
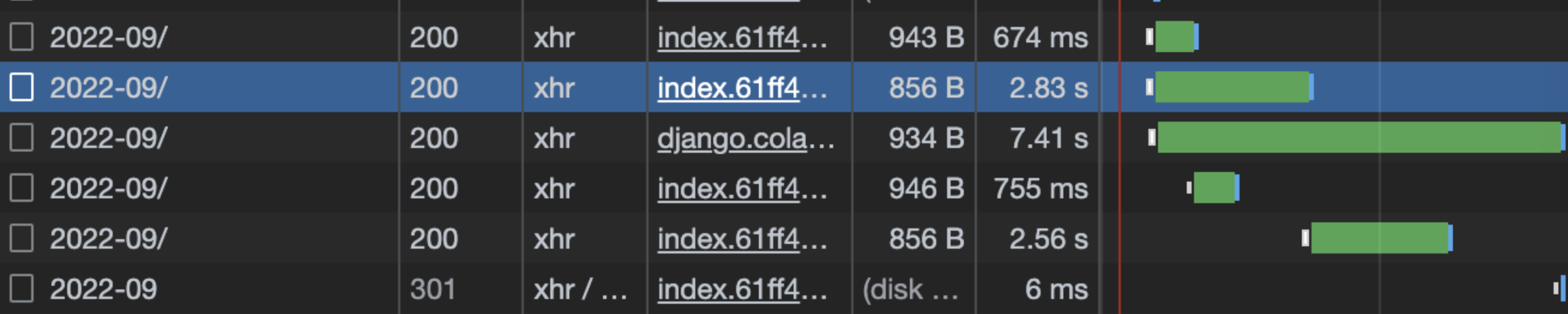
After (Optimized API)
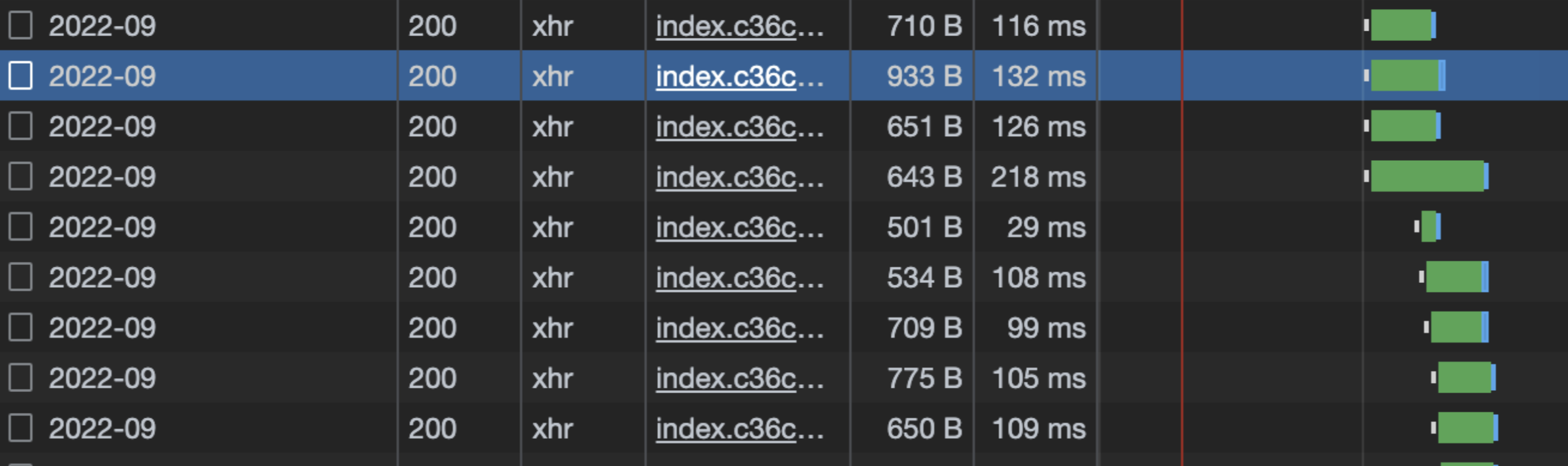
정량적 성과:Quantitative Results:
| 지표Metric | Before | After | 개선율Improvement |
|---|---|---|---|
| 전체 API 평균 응답 속도Overall API Avg Response Time | 500 ~ 1,000ms | 100 ~ 200ms | 약 80% 향상~80% improvement |
| 대규모 팀 스페이스 (10,000+ 유저)Large Team Space (10,000+ users) | 3,000 ~ 7,000ms | 200ms | 최대 97% 향상 (35x 가속)Up to 97% improvement (35x speedup) |
4-2. Staking Service4-2. Staking Service
개요Overview
| 항목Item | 내용Details |
|---|---|
| 서비스Service | Gracy Staking — ERC20 토큰Token Flexible Staking |
| 운영 기간Operation Period | 2023.06 ~ 2025.09 (약 2년 3개월, 9개 시즌 운영)Jun 2023 – Sep 2025 (~2 years 3 months, 9 seasons) |
| 토큰Token | Gracy Token (Bithumb 상장, ERC20)Gracy Token (Listed on Bithumb, ERC20) |
| 링크Link | https://staking.gracy.ai/ |
Bithumb에 상장된 ERC20 기반 Gracy Token의 Flexible Staking(유동형 스테이킹) 서비스를 설계 및 운영했다.Designed and operated a Flexible Staking service for the ERC20-based Gracy Token listed on Bithumb.
Smart Contract 개발Smart Contract Development
- APE Staking Contract를 레퍼런스로, Gracy 서비스 요구사항에 맞는 Staking Smart Contract(Solidity) 구현
- 불필요한 메소드 제거 및 요구사항별 신규 메소드 추가
- Removed unnecessary methods and added new methods per requirements
- Haechi Labs KALOS Audit 통과 — 보안 감사를 거친 검증된 컨트랙트Passed Haechi Labs KALOS Audit — security-audited and verified contract
Staking History 추적 시스템Staking History Tracking System
사용자의 모든 스테이킹 관련 온체인 액션(Stake / Claim / Withdraw)을 추적하여 DB에 기록하는 이중화 시스템을 설계했다.Designed a redundant system that tracks all user on-chain staking actions (Stake / Claim / Withdraw) and records them in the DB.
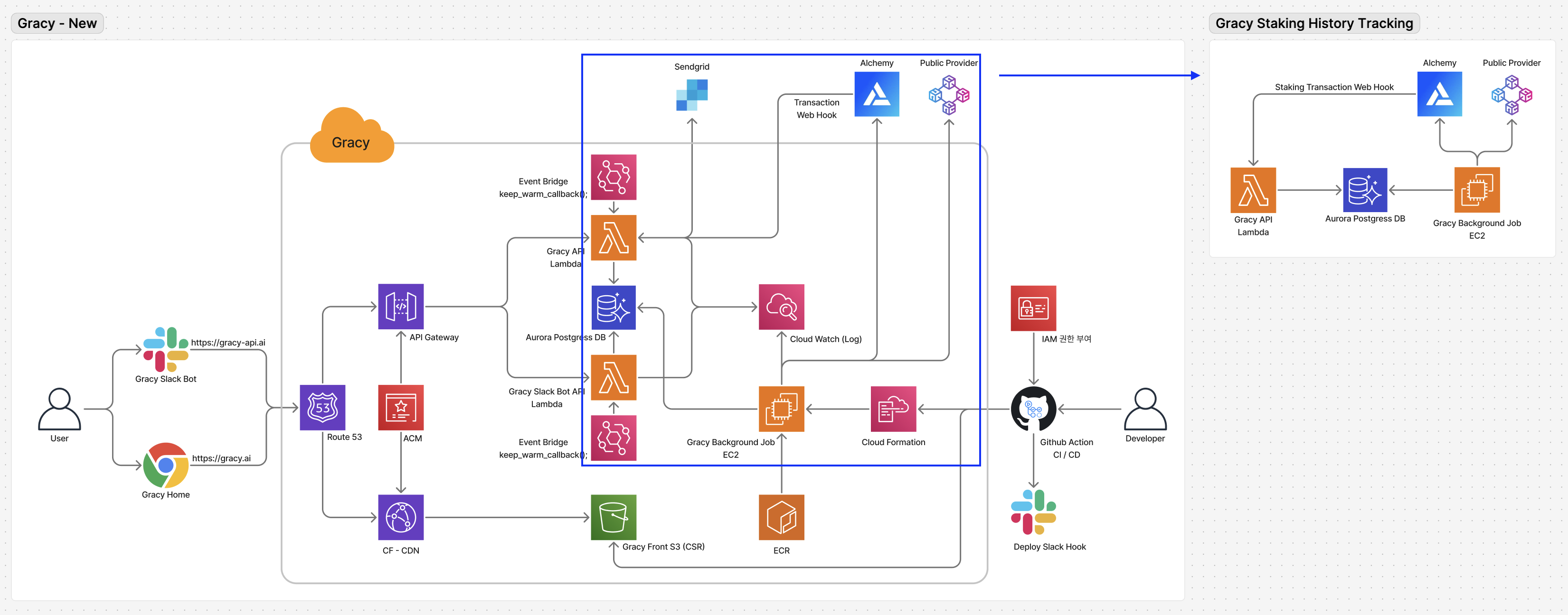
Phase 1: Provider WebHook 기반 실시간 수집Phase 1: Real-time Collection via Provider WebHook
사용자의 Stake / Claim / Withdraw 온체인 이벤트를 서버에서 인지해야 하지만, 블록체인은 Push 메커니즘이 없어 이벤트 수집 체계를 직접 구축해야 했다. Alchemy Notify를 활용하여 Gracy Staking Contract 이벤트를 실시간으로 감지하고, WebHook을 통해 Gracy API로 전달하는 방식을 채택했다.The server needed to detect user's on-chain Stake / Claim / Withdraw events, but blockchain has no push mechanism — requiring a custom event collection system. Alchemy Notify was utilized to detect Gracy Staking Contract events in real-time and deliver them to the Gracy API via WebHook.

한계:Limitations:
- 외부 서비스(Alchemy)에 대한 강한 의존성 — Alchemy 서버 불안정 시 Gracy Staking 서비스에도 동시 장애 전파Strong dependency on external service (Alchemy) — Alchemy server instability propagates failures to Gracy Staking service
- 간헐적 WebHook 누락 발생 → 사용자 스테이킹 History 정합성 문제Intermittent WebHook delivery failures → data consistency issues in user staking history
Phase 2: Background Watcher Job 도입 (이중화)Phase 2: Background Watcher Job (Redundancy)
WebHook 방식의 안정성 한계를 보완하기 위해, 자체 Background Job을 구현하여 이중 수집 체계를 구축했다.To compensate for WebHook reliability limitations, implemented a custom Background Job to establish a dual-collection system.

- 매분 Gracy Staking Contract에서 발생한 Event Log를 직접 수집Directly collects Event Logs from Gracy Staking Contract every minute
- WebHook에서 누락된 이벤트가 있는지 검증하고 자동 동기화Verifies if any events were missed by WebHook and auto-syncs
- 역할 분리: 실시간성은 Alchemy WebHook, 데이터 정합성 보장은 Background WatcherRole Separation: Alchemy WebHook for real-time delivery, Background Watcher for data consistency
이 이중 수집 체계로 WebHook 누락으로 인한 History 불일치 문제를 해소하여, 다른 팀원에게 인수인계 후 별도 개입 없이도 9개 시즌(약 2년 3개월) 동안 데이터 정합성 100%를 유지했다.This dual-collection system resolved History inconsistency caused by WebHook gaps, maintaining 100% data consistency across 9 seasons (~2 years 3 months) without any additional intervention after handover.
Phase 3: Public Provider CirculatorPhase 3: Public Provider Circulator
WebHook + Background Watcher 이중 수집 구조가 안정화된 이후, 비용과 의존성 문제를 해결하기 위해 Provider Circulator 모듈을 구현했다.After stabilizing the WebHook + Background Watcher dual-collection architecture, implemented the Provider Circulator module to address cost and dependency issues.
문제:Problem:
- Alchemy 단일 Provider로 WebHook + 매분 Contract Event 조회를 모두 처리 → 사용량 비용 증가Single Alchemy Provider handling both WebHook + per-minute Contract Event queries → increasing usage costs
- Alchemy 서비스 하나에 대한 강한 의존성 지속Continued strong dependency on a single Alchemy service
해결:Solution:
- ChainList 등에서 약 20개의 무료 Public Provider를 수집하여 풀(Pool) 구성Assembled a pool of ~20 free Public Providers from ChainList and other sources
- 각 Provider별 Latest Block Number 및 Health Status를 주기적으로 체크하고 DB에 캐싱Periodically checked Latest Block Number and Health Status per Provider and cached in DB
- 가장 최신 Block을 보유한 건강한 Provider를 자동으로 선택하는 Circulator 모듈 구현Implemented a Circulator module that automatically selects the healthiest Provider with the latest Block
- 모든 Public Provider가 비정상일 경우에만 유료 Alchemy Provider로 FallbackFalls back to paid Alchemy Provider only when all Public Providers are unhealthy
성과:Results:
- Alchemy 전체 사용량 대비 70~80% 비용 절감70–80% cost reduction in total Alchemy usage
- 단일 Provider 장애에 대한 내결함성(Fault Tolerance) 확보Achieved fault tolerance against single Provider failures
5. 성과 요약5. Results Summary
| 영역Area | 성과Achievement |
|---|---|
| 아키텍처Architecture | Monolithic EC2 → Serverless Lambda + EC2 Worker 하이브리드 전환, 도메인 분리 (HR API + Slack Bot API + Background Worker)Monolithic EC2 → Serverless Lambda + EC2 Worker hybrid migration, domain separation (HR API + Slack Bot API + Background Worker) |
| 인프라 비용Infra Cost | 서버 운용 비용 50~60% 절감 (고사양 상시 EC2 → 요청 기반 Lambda + 경량 EC2 Worker)Server operation cost reduced by 50–60% (high-spec always-on EC2 → pay-per-request Lambda + lightweight EC2 Worker) |
| API 성능API Performance | 전체 API 평균 응답 속도 80% 향상 (500~1,000ms → 100~200ms)Overall API avg response time 80% improvement (500–1,000ms → 100–200ms) |
| 대규모 처리Large-scale | 10,000+ 유저 팀 스페이스에서 최대 97% 성능 향상 (7,000ms → 200ms)Up to 97% performance improvement for 10,000+ user team spaces (7,000ms → 200ms) |
| 스테이킹Staking | 9개 시즌 안정 운영, Haechi Labs 보안 감사 통과9 seasons of stable operation, passed Haechi Labs security audit |
| 블록체인 비용Blockchain Cost | Public Provider Circulator로 Alchemy 비용 70~80% 절감70–80% Alchemy cost reduction via Public Provider Circulator |
| 운영 안정성Operational Stability | WebHook + Background Watcher 이중화로 데이터 정합성 보장Data consistency guaranteed via WebHook + Background Watcher redundancy |