BWAI (Bad Words AI)BWAI (Bad Words AI)
NLP 기반 한국어 비속어 탐지 시스템NLP-based Korean Profanity Detection System
1. 프로젝트 개요1. Project Overview
NLP를 이용한 한국어 기반 비속어 탐지 솔루션 (Open API로 제공)NLP-based Korean Profanity Detection Solution (Provided as Open API)
| 항목Item | 내용Details |
|---|---|
| 프로젝트명Project | BWAI (Bad Word AI) |
| 분류Category | NLP 기반 한국어 비속어 탐지 시스템NLP-based Korean Profanity Detection System |
| 개발 기간Duration | 8개월 (2020.05 ~ 2020.12)8 months (May 2020 – Dec 2020) |
| 팀 규모Team Size | 3명 (BE 1, AI/ML 1, FE 1)3 members (BE 1, AI/ML 1, FE 1) |
| 역할Role | Backend DeveloperBackend Developer |
| 과정Program | 소프트웨어 마에스트로 11기Software Maestro 11th Cohort |
| GitHub | https://github.com/BWAI-SWmaestro |
| 인터뷰Interview | https://www.youtube.com/watch?v=p3rg0xTY_D4 https://swmaestro.ai/sw/bbs/B0000006/view.do?nttId=23420 (SW마에스트로 사이트 접속이 느릴 수 있습니다SW Maestro site may load slowly) |

2. 프로젝트 배경과 동기2. Background and Motivation
2020년 당시 대부분의 한국어 욕설 탐지 시스템은 사전 기반 Rule-Base 매칭 방식이었다. 비속어 사전에 등록된 문자열이 입력 텍스트에 포함되어 있는지를 단순 문자열 매칭으로 판별하는 구조였다.In 2020, most Korean profanity detection systems relied on dictionary-based rule-base matching — simply checking whether the input text contained any string registered in a profanity dictionary.
| 유형Type | 입력 텍스트Input Text | Rule-Base 판정Rule-Base Result | 실제 의미Actual Meaning |
|---|---|---|---|
| False Positive (오탐false alarm) | "아저씨 발에서 냄새가 납니다""Sir, your feet smell" (Korean) | "씨발" 탐지 → 욕설Detects substring "씨발" → Profanity | 정상 문장Normal sentence |
| False Negative (미탐miss) | "너희 어머니 살아계시지?""Is your mother still alive?" (Korean) | 사전 매칭 없음 → 정상No dictionary match → Normal | 문맥상 악의적 표현Contextually malicious expression |
이를 해결하기 위해 NLP를 활용하여, 문맥 수준에서 비속어 여부를 판별하는 하이브리드 AI 모델을 개발하고, Open API 형태로 외부 서비스에 제공하는 것을 목표로 했다.To solve this, the goal was to develop a hybrid AI model that determines profanity at the context level using NLP techniques, and provide it to external services as an Open API.
| 분류Category | 기술Technology |
|---|---|
| Language | Python |
| Framework | Flask |
| Database | MongoDB |
| NLP / ML | KcBERT, FastText, LDA (Latent Dirichlet Allocation) |
| Infra | AWS Lambda (Zappa), EC2, ALB, S3 + CloudFront, Route53, ACM, EventBridge, SSM |
3. 기술 선택과 근거3. Technology Choices and Rationale
2020년 시점은 LLM이 상용화되기 이전이었으므로, 당시 가용한 NLP 기법들을 조합하여 최적의 솔루션을 구성하는 것이 핵심 과제였다.As this was before LLMs were commercially available in 2020, the key challenge was composing an optimal solution by combining available NLP techniques.
| 기술Technology | 선택 근거Rationale |
|---|---|
| KcBERT | 띄어쓰기 오탐 문제를 서브워드 단위로 해결해야 했다. 한국어 댓글 데이터로 사전 학습된 KcBERT는 구어체 / 비속어 / 신조어 어휘가 풍부하여, 서브워드 토크나이저가 "아저씨 발에서" → "씨발" 오탐을 원천 차단할 수 있었다Needed to resolve false positives from word spacing at the subword level. KcBERT, pre-trained on Korean comment data, has a rich vocabulary of colloquial / profanity / neologisms, and its subword tokenizer fundamentally prevents false detection of "씨발" in "아저씨 발에서" |
| FastText | 명시적 욕설 없이도 악의적인 문장을 탐지하려면, 악성 코퍼스와의 의미적 유사도를 측정해야 했다. 한국어 조사 변형과 오타에 강건한 서브워드 기반 FastText가 적합했다To detect malicious sentences without explicit profanity, semantic similarity against a malicious corpus was needed. Subword-based FastText, robust against Korean particle variations and typos, was the right fit |
| LDA | FastText만으로는 단어 수준 유사도에 그쳤다. 악성 문서의 주제적 패턴을 추출하여 문서 수준의 분류를 보강할 수 있는 LDA를 결합했다FastText alone only measured word-level similarity. LDA was combined to extract thematic patterns from malicious documents and reinforce document-level classification |
4. 하이브리드 NLP 모델4. Hybrid NLP Model
단일 기법으로는 한국어 비속어의 다양한 패턴을 커버할 수 없었기 때문에, 명시적 비속어 탐지와 문맥 기반 악성 표현 탐지를 결합한 하이브리드 파이프라인을 설계했다.Since no single technique could cover the diverse patterns of Korean profanity, a hybrid pipeline was designed combining explicit profanity detection and context-based malicious expression detection.
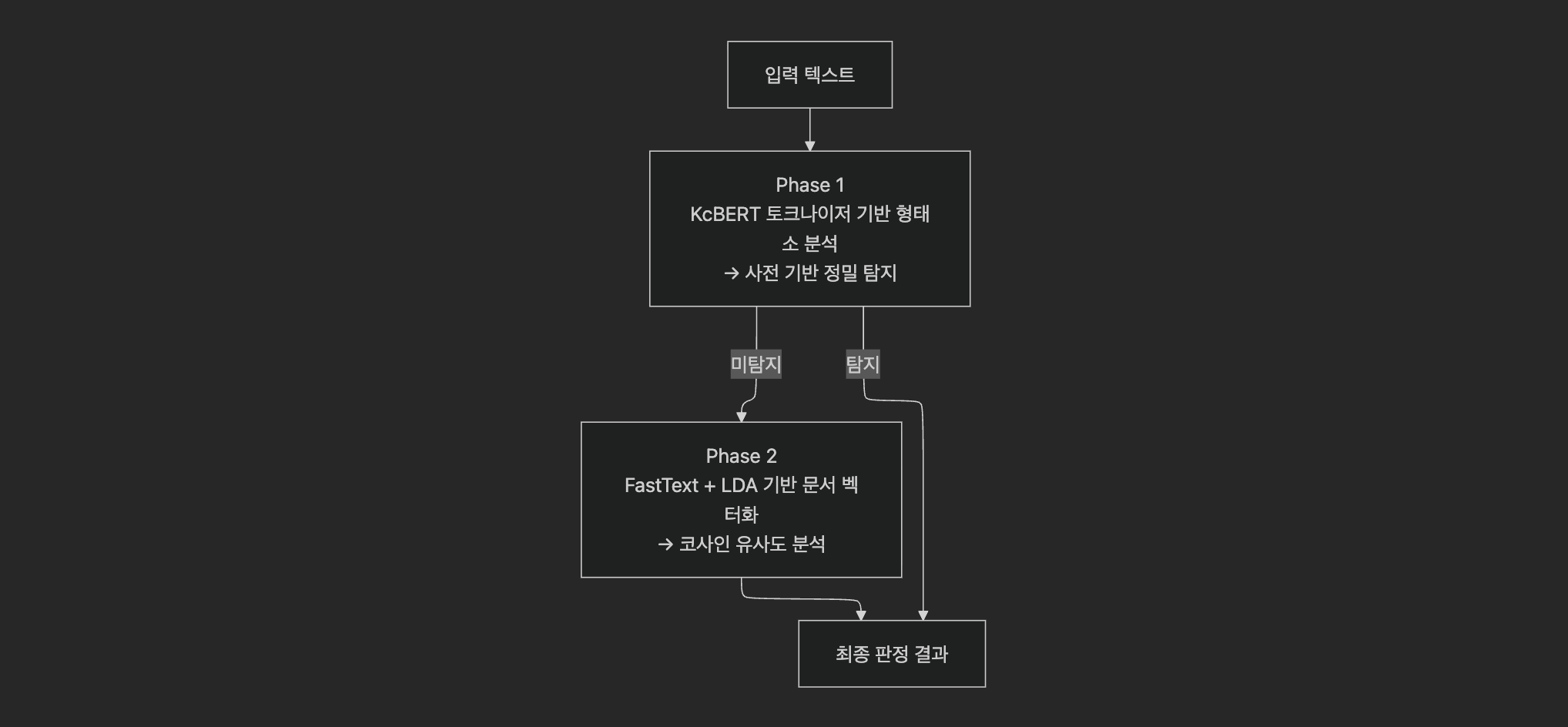
Phase 1: KcBERT 서브워드 토크나이저 기반 탐지Phase 1: KcBERT Subword Tokenizer-based Detection
기존 Rule-Base의 가장 큰 문제인 띄어쓰기 오탐을 해결하기 위해, 단순 문자열 매칭 대신 서브워드 단위 토큰 매칭을 도입했다.To solve the biggest problem of existing Rule-Base systems — false positives from word spacing — subword-level token matching was introduced instead of simple string matching.
| 입력Input | Rule-Base (문자열 매칭)Rule-Base (String Matching) | Phase 1 (서브워드 분석)Phase 1 (Subword Analysis) |
|---|---|---|
| "아저씨 발에서 냄새" | "씨발" 탐지 (오탐)"씨발" detected (false positive) | ["아저씨", "발", "에서", "냄새"] → 정상["아저씨", "발", "에서", "냄새"] → Normal |
| "씨발 진짜 화난다" | 탐지Detected | ["씨발", "진짜", "화난다"] → 욕설 탐지["씨발", "진짜", "화난다"] → Profanity detected |
| "ㅅㅂ 뭐하냐" | 사전에 없음 (미탐)Not in dictionary (missed) | 초성 패턴 매칭 가능Consonant-initial pattern matching possible |
Phase 2: FastText + LDA 기반 문맥적 악성 표현 탐지Phase 2: Contextual Malicious Expression Detection via FastText + LDA
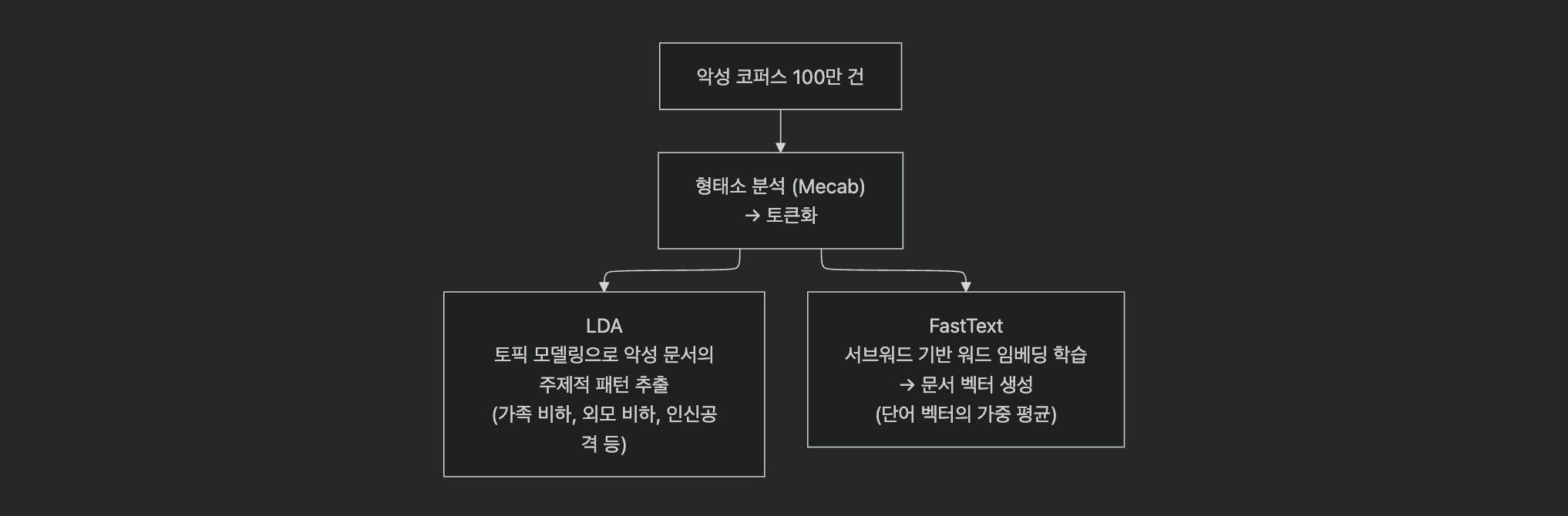
Phase 1은 명시적 비속어를 정확히 잡아내지만, "너희 어머니 살아계시지?"처럼 욕설 단어 없이도 악의적인 문장은 탐지할 수 없다. 이를 해결하기 위해 대규모 악성 텍스트 코퍼스 기반의 문맥 유사도 분석을 도입했다.Phase 1 accurately catches explicit profanity, but cannot detect malicious sentences without any profane words, such as "Is your mother still alive?" To address this, context similarity analysis based on a large-scale malicious text corpus was introduced.
DCInside, 일간베스트 등 비속어 빈출 커뮤니티에서 약 100만 건의 게시글 / 댓글 데이터를 수집하고, 악성 / 비악성 라벨링을 통해 학습 데이터셋을 구축했다. 학습된 FastText + LDA 모델로 입력 텍스트의 문서 벡터를 생성하고, 악성 코퍼스와의 코사인 유사도를 계산하여 문맥적 악성 여부를 판정한다.Approximately 1 million posts / comments were collected from profanity-heavy communities such as DCInside and Ilbe, and a training dataset was built through malicious / non-malicious labeling. The trained FastText + LDA model generates a document vector for the input text and calculates cosine similarity against the malicious corpus to determine contextual maliciousness.
모델 성능 개선Model Performance Improvement
1차 학습(KoBERT 기반)에서 F1 0.80을 달성한 후, 비속어 도메인에 특화된 사전 학습 모델(KcBERT)로 전환하고 학습 데이터를 보강하여 반복 학습을 진행, 최종 홀드아웃 테스트셋 기준 F1 0.94까지 개선했다.After achieving F1 0.80 in the 1st training round (KoBERT-based), switched to a profanity domain-specialized pre-trained model (KcBERT) and augmented training data through iterative training, ultimately improving to F1 0.94 on the holdout test set.
5. 성과 및 임팩트5. Results and Impact
소프트웨어 마에스트로 11기를 수료하며, 100만 건 규모의 악성 코퍼스 기반 하이브리드 NLP 모델을 F1 0.94까지 끌어올렸다. LLM 상용화 이전 시점에서 전통 NLP 기법(KcBERT, FastText, LDA)을 조합하여, 단순 사전 매칭의 한계를 넘어 문맥 기반 욕설 탐지의 실용적 솔루션을 제시한 프로젝트였다.Completed Software Maestro 11th Cohort, building a hybrid NLP model based on a 1M malicious corpus and achieving F1 0.94. Prior to LLM commercialization, this project presented a practical solution for context-based profanity detection by combining traditional NLP techniques (KcBERT, FastText, LDA), going beyond simple dictionary matching.
아쉽게도 사업성은 인정받지 못해 실제 Open API로 외부 제공은 성공을 거두지 못했으나, 각 팀원들이 속한 대학교 구성원들이 편하게 프로젝트 개발에 사용될 수 있도록 약 2개월간 무료로 API를 제공해주었다.Although the business viability was not recognized and the Open API did not achieve commercial success, the API was provided free of charge for approximately 2 months for use in projects at each team member's university.